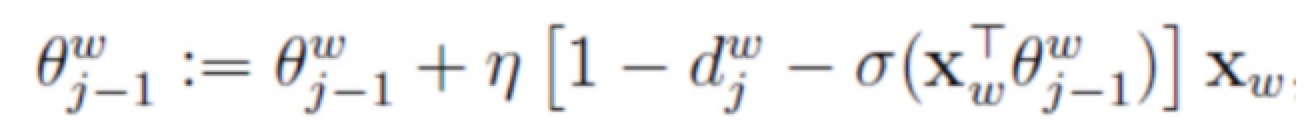找出最后一个以’.’开始的字符串
1 | # 第一种方法 |
获取某文件夹下包含文件名称的绝对路径
1 | def all_path(dirname): |
获取文件下文件名称的另一种方式
1 | result = [] |
还是获取文件列表到一个list,并排序
glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:1
2
3
4
5import glob
list_1 = glob.glob('*.jpg')
# ['2.jpg', '1.jpg', '5.jpg']
sorted(list_1)
# ['1.jpg', '2.jpg', '5.jpg']
3种连接字符串方式
1 | seq1 = ['hello','good','boy','doiido'] |
分割字符串成list
1 | line = "我们 大 中国" |
删除不同位置的空格
1 | s.strip(rm) #删除s字符串中开头、结尾处,位于rm删除序列的字符 |
python全局变量
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块是不会引入新的作用域的。1
2
3
4
5
6
7
8
9
10
11
12if True:
msg = 'I am from Runoob'
print(msg) # 'I am from Runoob'
#=============global=======nonlocal===================
global str1 # 在给全局变量str1赋值时,需要先声明global,否则str1会被当作新定义的局部变量
str1 = "new year"
str2 = str1 # 全局变量赋值给另一个局部变量时,不需global声明,程序会先找局部变量str1,没得话就去全局变量区域找
def func():
str1 = "中国"
def func_1():
nonlocal str1
str1 = "南京" #修改嵌套作用域(函数A的变量作用在子函数B时)中的变量需要使用 nonlocal 关键字
python list、dict、tuple、set
set:通过set.add()函数添加元素,set会自动去重,且查找效率高(hash)
tuple是只读的list(),list可以通过下标、循环等方式访问,通过.append()来访问
dict是key、value一一对应的关系,常用于序号跟真值之间的查询,比如NMT任务的vocab1
2
3
4dict1 = {'1':'飞机','2':'自行车','3':'鸟','4':'船','5':'瓶子','6':'公共汽车','7':'车','8':'猫','9':'椅子','10':'牛','11':'餐桌','12':'狗', \
'13':'马','14':'摩托车','15':'人','16':'植物','17':'羊','18':'沙发','19':'火车','20':'电视'}
for str_i in list(A):
List.append(dict1[str_i]) #listA中是一个纯数字列表,LIST中对应其在字典中的真实类别
write、writelines区别
1 | f.write(name + '\n') # write只能写入str |
文件批量命名
1 | import os |