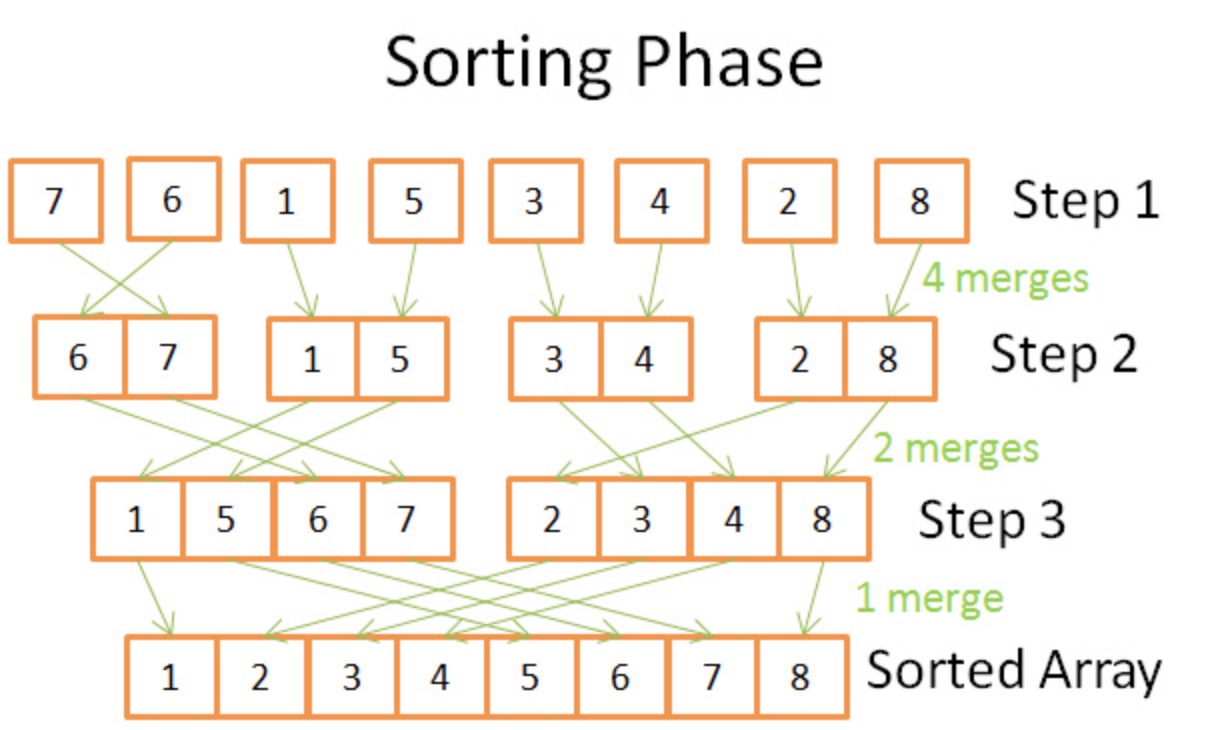
Ubuntu1604系统安装
笔者第一次尝试Mac烧系统盘,没想到比windows简单到爆,过程如下:
官网下载Ubuntu iso文件
格式化一个U盘
接着写入U盘镜像1
2
3df -hl # 记住磁盘名称,Eg:/dev/disk2s
sudo diskutil umount /dev/disk2s # 卸载该磁盘
sudo dd bs=1m if=/Users/<user name>/Desktop/ubuntu-16.04.4-desktop-amd64.iso of=/dev/disk2s
静静等待10分钟,U盘即可写入完毕。接着就是设置电脑U盘启动,开始安装Ubuntu系统了
ubuntu 换源
清华大学开源软件镜像站寻找对应系统的源1
2
3
4
5
6
7
8
9
10
11cd /etc/apt
sudo cp sources.list sources.list.old #先将之前的源做个备份
vi sources.list # 拷贝清华的镜像到该list
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiver
sudo apt-get update # 更新源完成,发现网速飞快了
apt-get相关常用指令
1 | sudo apt-get update 更新源 |
显卡驱动安装
Nvidia显卡驱动踩了很多坑,到网上百度了N多教程,大致尝试的如下:
- 显卡线插集显上,装好驱动后把线再插回N卡
- BIOS设置禁用Secure boot,cpu做显卡
- 采用PPA源,尝试各种375、381、390的安装
- 打开ubuntu的软件更新,更新显卡驱动
经过上述步骤,会提示显卡驱动已经安装成功,但nvidia-smi依然无效…该最简单但最高效的选手登场了
编译 NVIDIA 驱动程序
Nvidia官网下载最新的显卡驱动程序,ubuntu的一般就几十兆左右。
将nouveau driver加入黑名单1
2
3vi /etc/modprobe.d/blacklist.conf
blacklist nouveau
options modset=0
输入如下命令使驱动禁用生效1
sudo update-initramfs -u
终端输入lspci | grep nouveau,如果没有显示证明该驱动被kill1
reboot # 一定要重启
杀掉LightDM或GDM登录显示器,进入纯文本tty1模式1
2sudo service lightdm stop
sudo dpkg-reconfigure gdm # 有的人可能安装的不是LightDM界面,可先通过该命令切到LightDM,或者直接stop GDM等界面(第二种笔者未尝试)
编译安装NVIDIA驱动,此过程大约耗时3~5分钟1
2chmod +x NVIDIA-xxx.run
sudo ./NVIDIA-xxx.run
需要注意的:
1、此处认真看提示,并不是一路选择”yes”。
2、假如上一步在安装时,Warning了gcc版本不对,则退出驱动安装,先安装对应版本的gcc之后再继续。笔者安装的驱动程序提示需要gcc-5.4.0,又是一番折腾,还好在冯博的指导下,找到了精干快速的方法。不介意的话可以移步笔者之前的文章Ubuntu下gcc/g++多版本切换
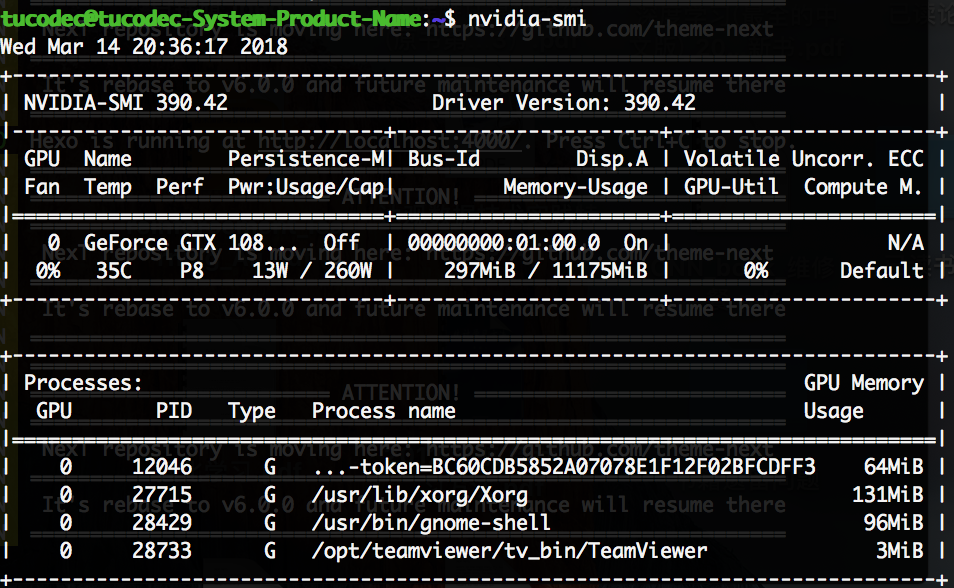
安装成功后,重新开启桌面测试。1
2sudo service lightdm start
nvidia-smi
成功后的截图
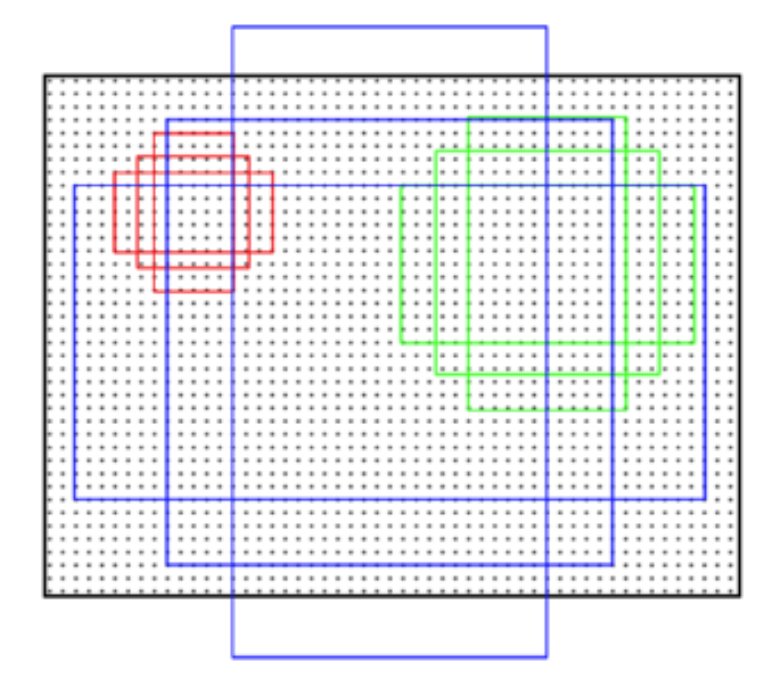
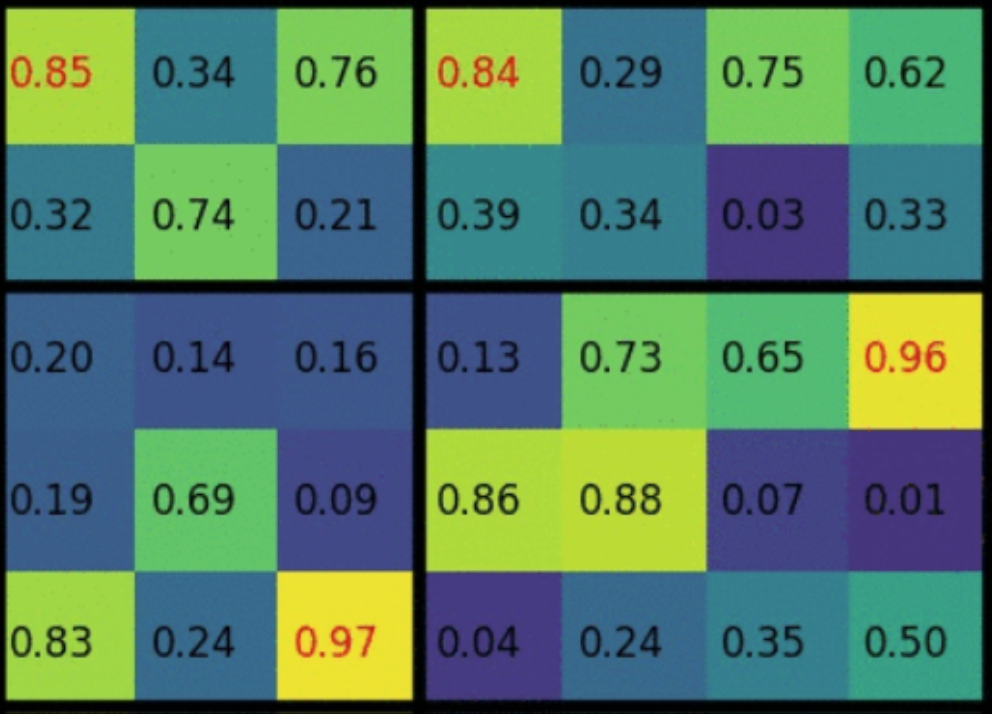

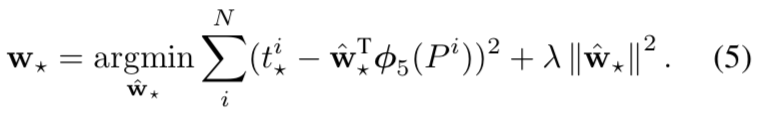
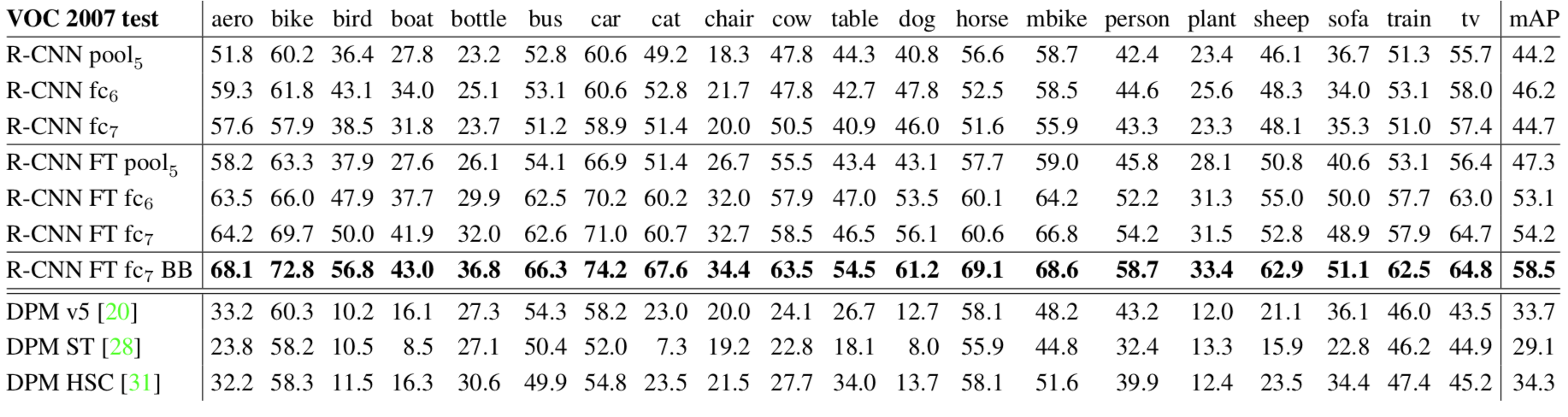

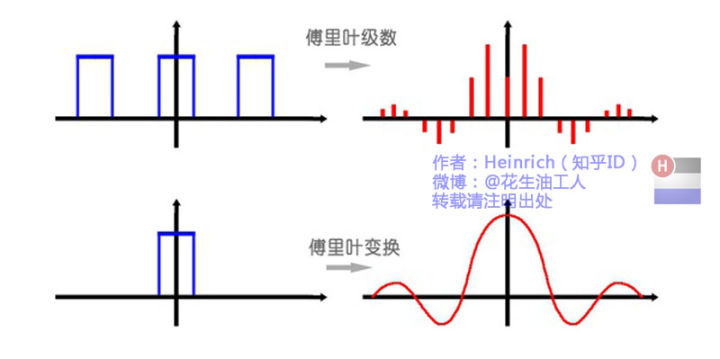
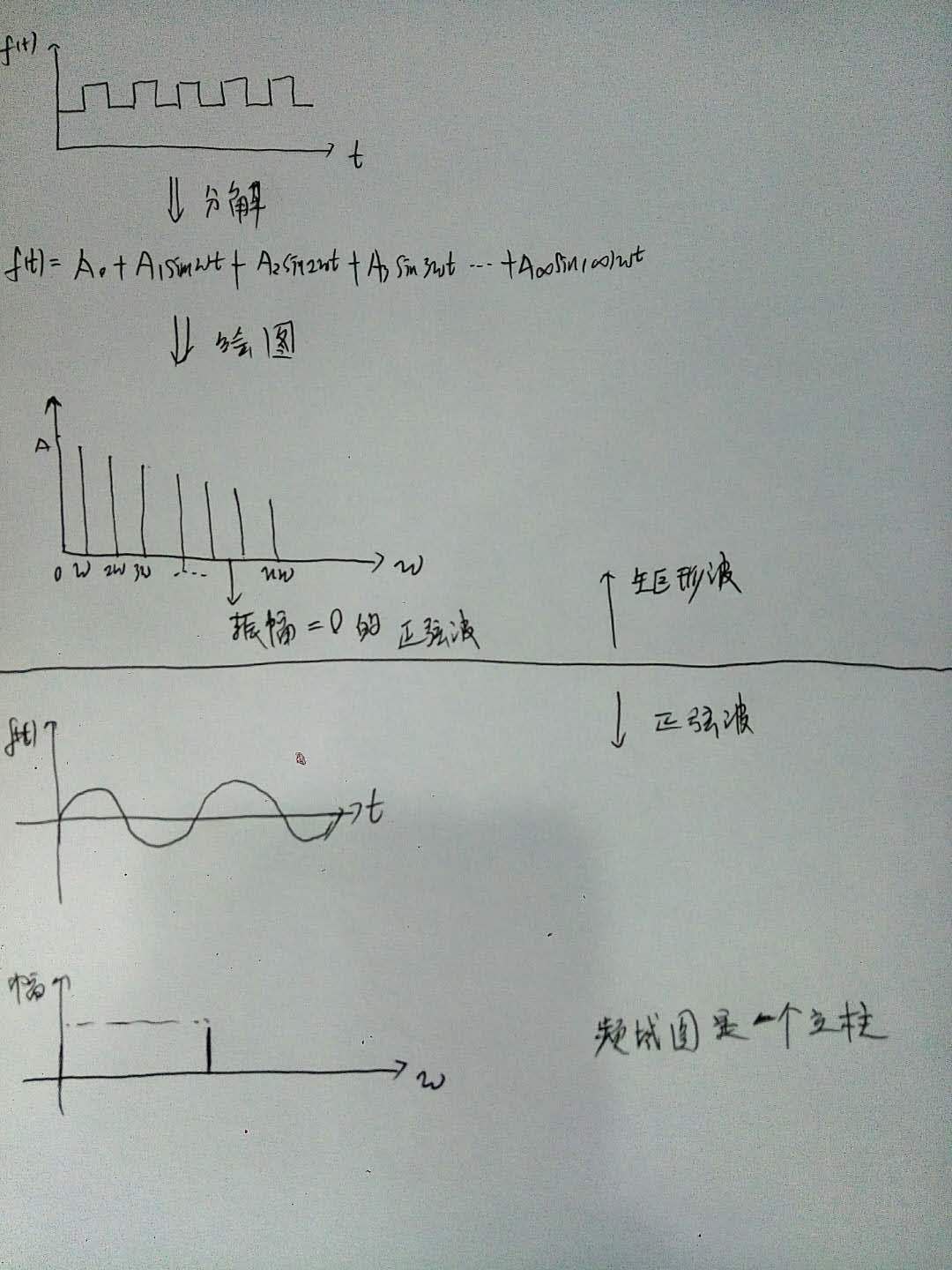
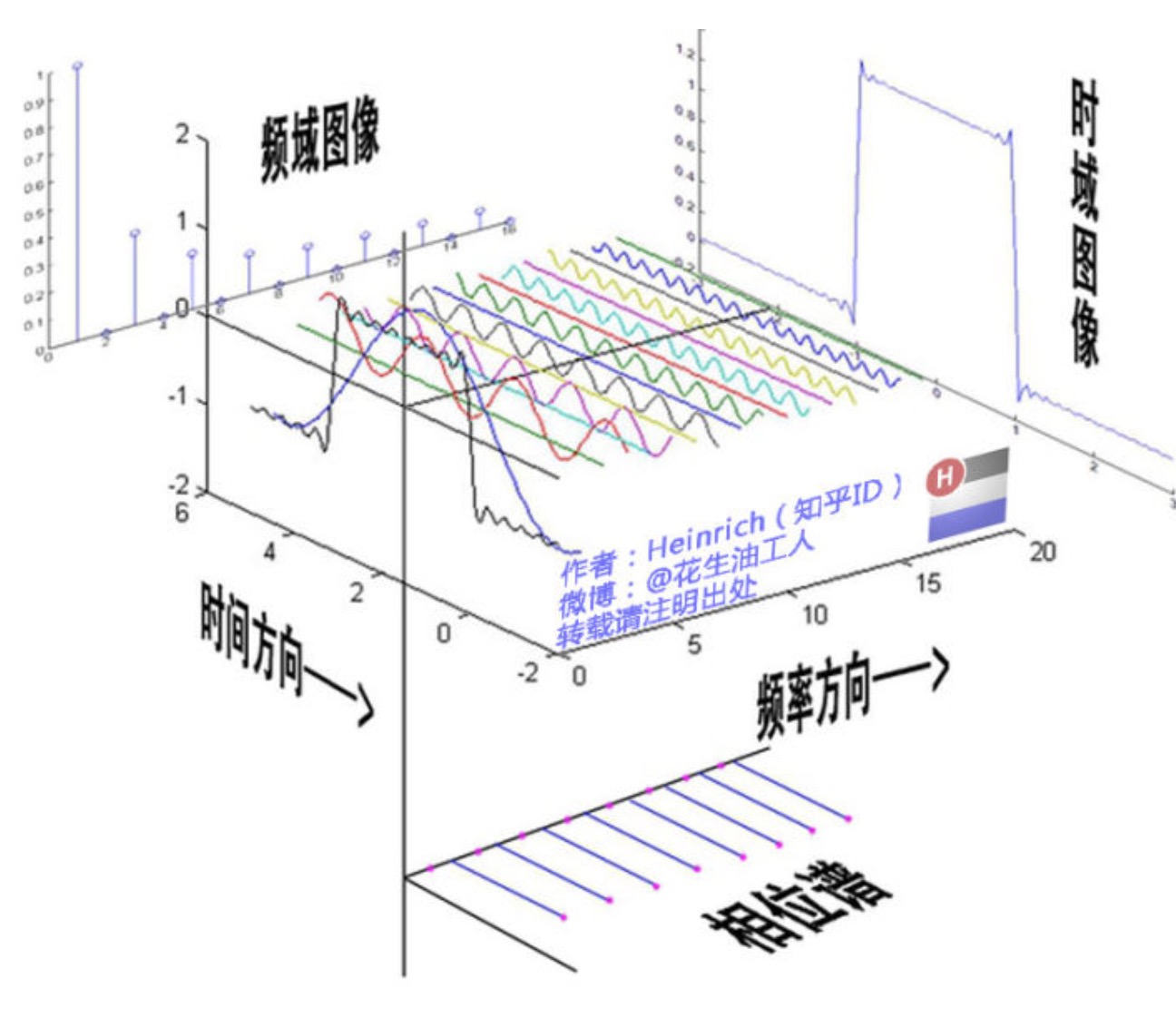
 小结:这样的特性说明了两个问题,物体识别时候,需要充分考虑图像物体的多样性(diversity),单一特征可能分得乱七八糟;另外,图像中物体布局有一定的层次(hierarchical)关系,在算法中的体现就是从小区域开始,一步步分层而上进行合并。
小结:这样的特性说明了两个问题,物体识别时候,需要充分考虑图像物体的多样性(diversity),单一特征可能分得乱七八糟;另外,图像中物体布局有一定的层次(hierarchical)关系,在算法中的体现就是从小区域开始,一步步分层而上进行合并。 重点翻译:
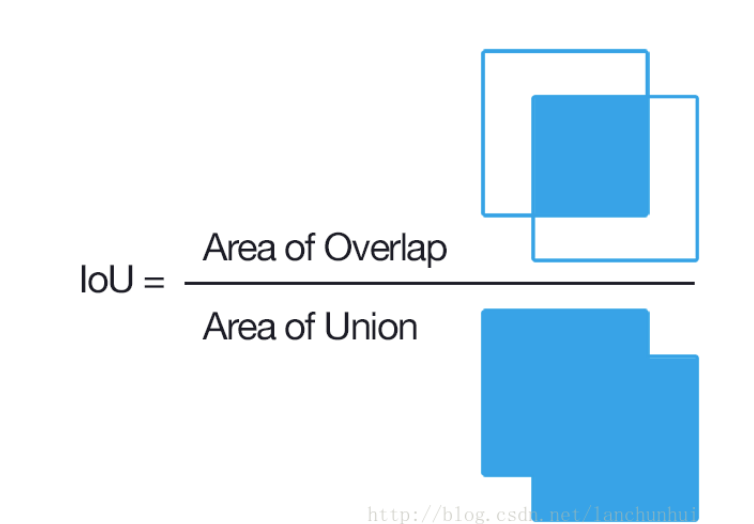
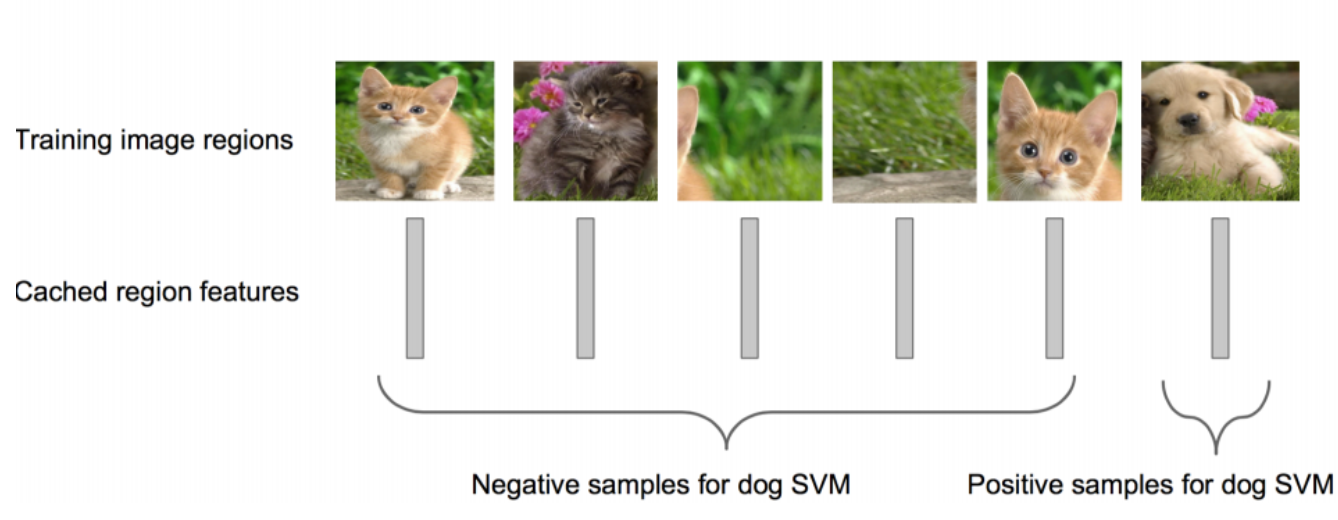
重点翻译: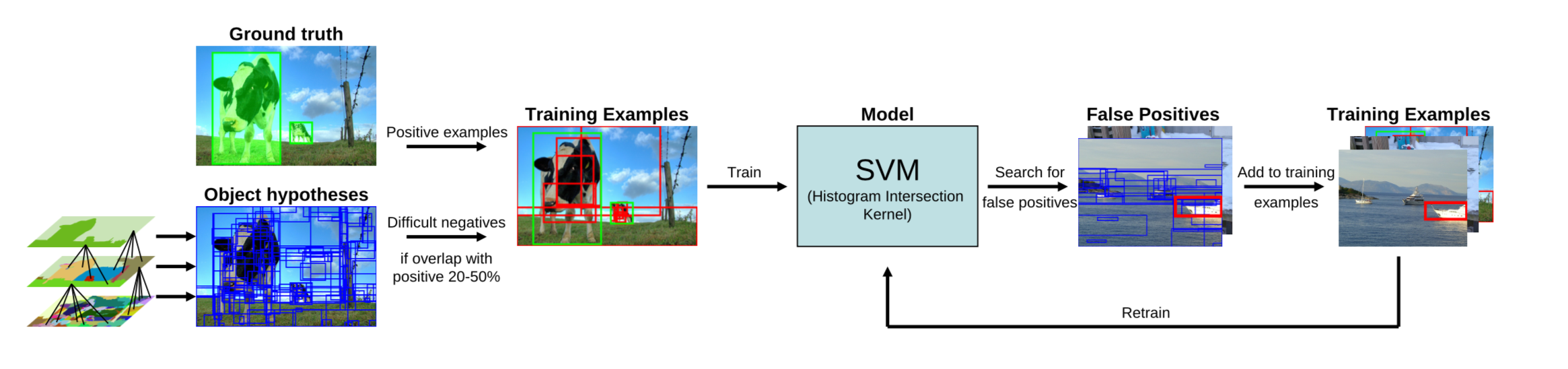 其中正样本为人工标注的bounding box,负样本为与正样本重叠程度20%~50%的Regions。特别地,删去负样本中,彼此重叠程度>70%的Regions。重复迭代过程中再加入hard negative example进行训练。
其中正样本为人工标注的bounding box,负样本为与正样本重叠程度20%~50%的Regions。特别地,删去负样本中,彼此重叠程度>70%的Regions。重复迭代过程中再加入hard negative example进行训练。