背景
即将学习基于R-CNN的图像目标检测(Object Recognition),不得不提的一篇论文是《Selective Search for Object Recognition》,虽然仅用了传统的机器学习算法Selective Search + DPM/Hog特征 + SVM分类器,但其结构简单,可解释性强,对后面的Deep Learning物体检测模型,都有很大的借鉴意义。
本篇论文的创新点在于选择性搜索算法(Selective Search)。不同于传统的蛮力搜索(Exhaustive Search):需要不断改变窗口大小,遍历整张图像。Selective Search可以选择性地找出物体可能的存在区域,节省了大量不必要的特征提取开销。
结论先行:如图红色的区域便是Selective Search算法提取的可能存在物体的窗口:
Selective Search算法描述
文章一开始便用这4幅图,说明了同一物体组成成分多样性的问题。图1显示了区分桌子和它上面的餐具需要利用一定的层次关系;图2的猫需要通过颜色来区分;图3的变色龙颜色不行,需要通过纹理特征(texture)来区分;图4中的车和车轮看似粘连在一起,但我们可以通过颜色、纹理两种特征加以区分。 小结:这样的特性说明了两个问题,物体识别时候,需要充分考虑图像物体的多样性(diversity),单一特征可能分得乱七八糟;另外,图像中物体布局有一定的层次(hierarchical)关系,在算法中的体现就是从小区域开始,一步步分层而上进行合并。
小结:这样的特性说明了两个问题,物体识别时候,需要充分考虑图像物体的多样性(diversity),单一特征可能分得乱七八糟;另外,图像中物体布局有一定的层次(hierarchical)关系,在算法中的体现就是从小区域开始,一步步分层而上进行合并。
Selective Search算法详解
Selective Search算法对传统的exhaustive search从以下两方面进行了改进:
- 采用多种先验知识对各个区域进行判别,避免一些无用的搜索,提高速度和精度
- Selective Search只负责快速生成可能存在物体的窗口,并不做具体的特征检测
执行流程图
 重点翻译:
重点翻译:
- input:彩色图像
- output:物体可能的位置(很多个矩形坐标)
- 首先借助这篇论文的方法,对图像实现一个粗略的分割:R = r1, r2…rn。调用方式比较简单,不再赘述,但要注意源图需是.ppm格式
- 初始化一个空集S
- 计算所有相邻区域之间的相似度,并放入S中(实质存放的是一个区域对,及其相似度信息)
- 找出S中相似度最高的两个区域进行合并,Eg:r1, r2,进行合并为r_t1。删除S中所有与r1, r2相邻的元素,并重新计算r_t1与周围相邻区域的相似度,放入集合S中,并将r_t1放入另一个集合R中。重复这个步骤,直到S为空。此时所有小区域被合并成为原图的大小,但每次的合并信息,都被存放在了集合R中,最后的
Combining Locations便是对R中的区域进行标号排序。- 从R中找出所有被标号的区域,计算其bounding box,便得到output。
PS:以上第三步的图像分割方法中考虑场景以及光照条件等影响,采用了RGB、灰度、HSV等8种颜色空间进行分割计算
相似度计算方式
相似度计算直接影响合并区域顺序,对最终的检测结果,有至关重要的影响。此处同样综合了多种维度的相似度信息,分别是颜色(color)相似度、纹理(texture)相似度、大小(size)相似度和吻合(fit)相似度,最终将4种相似度计算结果,用如下公式合并:$${s(r_{i}, r_{j})= a_{1}s_{colour}(r_{i}, r_{j}) + a_{2}s_{texture}(r_{i}, r_{j})
+a_{3}s_{size}(r_{i}, r_{j}) +a_{4}s_{fill}(r_{i}, r_{j})}$$
这里仅就图像的颜色空间相似度进行介绍
颜色是区分不同物体的一个重要因素,文中将每个Region的颜色信息统计成一个75维的直方图,即每一个颜色通道为25bins的直方图(255/25 == 9,25bins的意思就是每隔9个数值统计像素数量),之后用L1范数进行归一化(除以各维度绝对值之和)。相似度计算方式如下:$$s_{colour}(r_{i}, r_{j}) = \sum_{k=1}^{n}min(c\tfrac{k}{i},c\tfrac{j}{k})$$其实质就是计算两个直方图的交集,而新的区域特征向量采用如下与区域面积加权的方式实现。$$C_{t} = \frac{size(r_{i})\ast C_{i}+size(r_{j})\ast C_{j}}{size(r_{i})+size(r_{j})}$$而新区域面积就是两个源区域面积的简单相加$size(r_{i})+size(r_{j})$
Combining Locations
完成上述步骤,提取出了图像中大量的bounding box区域,而实际存在物体的区域可能只有其中的几个,这时候便需要对备选的bounding box赋予一定的优先级,从而进一步缩小后文特征提取的范围,文中称这一步处理为Combining Locations。
具体方法为:因为Selective Search是一个逐步合并的层级结构,所以最大的一张图标为’1’,合并成’1’的子图标为’2’、’3’,以此类推。但这样的话会造成越大的bounding box排序越靠前。所以作者又加入了一定的shuffle机制,即在每个序号前,乘上一个随机数$RAND\in (0,1)$。通过新计算出的数值,按从小到大排序,得出Region最终的排序结果。一般candidates数量为2K个
Object Recognition目标识别
接下来采用HOG/DPM等算子分别提取正负样本特征,加入SVM分类器进行训练,整个架构如图所示: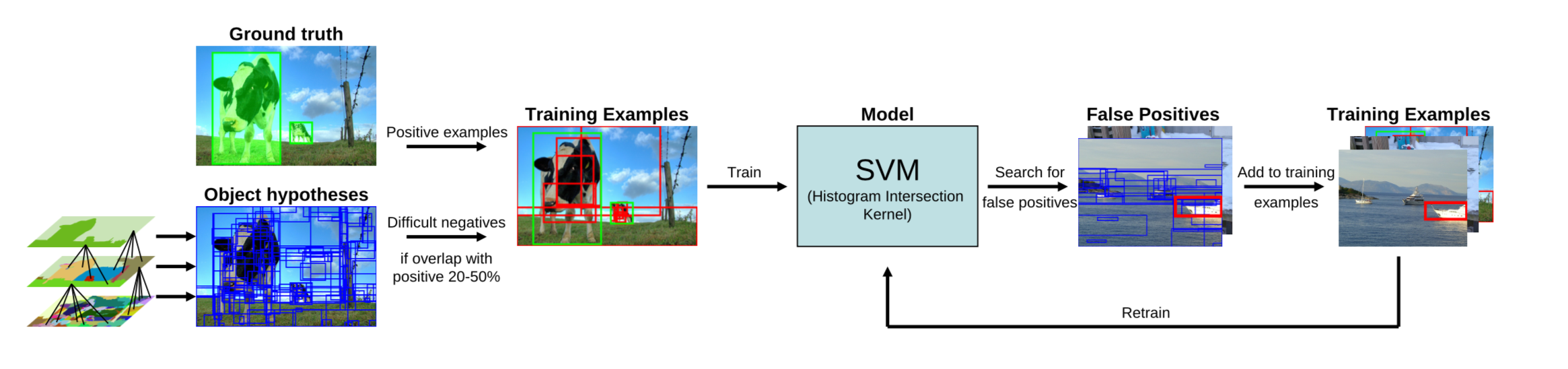 其中正样本为人工标注的bounding box,负样本为与正样本重叠程度20%~50%的Regions。特别地,删去负样本中,彼此重叠程度>70%的Regions。重复迭代过程中再加入hard negative example进行训练。
其中正样本为人工标注的bounding box,负样本为与正样本重叠程度20%~50%的Regions。特别地,删去负样本中,彼此重叠程度>70%的Regions。重复迭代过程中再加入hard negative example进行训练。
PS:重叠程度即IoU(intersection-over-union,是一个定位精度的评价标准)参数,计算图示如下所示: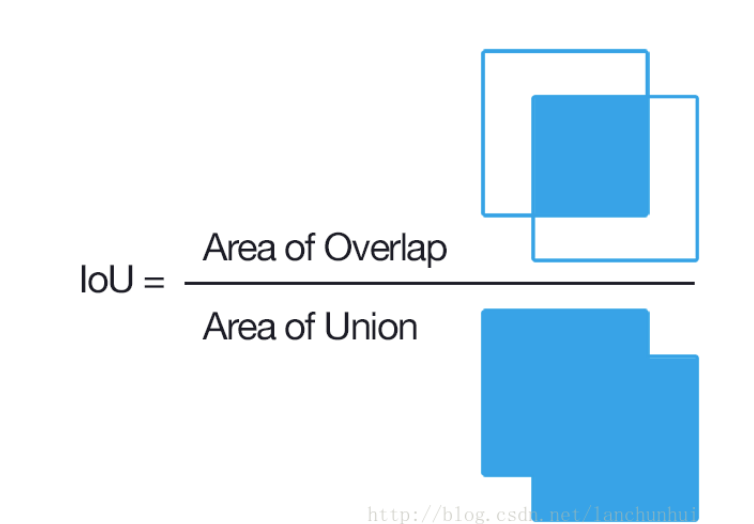
参考
📎:《Selective Search for Object Recognition》
📎:Selective Search算法的python实现
📎:Graph Based Image Segmentation
📎:http://blog.csdn.net/niaolianjiulin/article/details/52950797#t2
📎:http://jermmy.xyz/2017/05/04/2017-5-4-paper-notes-selective-search/