背景
本篇文章要介绍的,是神经网络应用于物体检测领域的开山鼻祖R-CNN:Regions with CNN features。检测整体框架如下图所示,相信在读过Selective Search的论文后,对上图的架构并不陌生(不介意的可移步笔者对Selective Search的解读)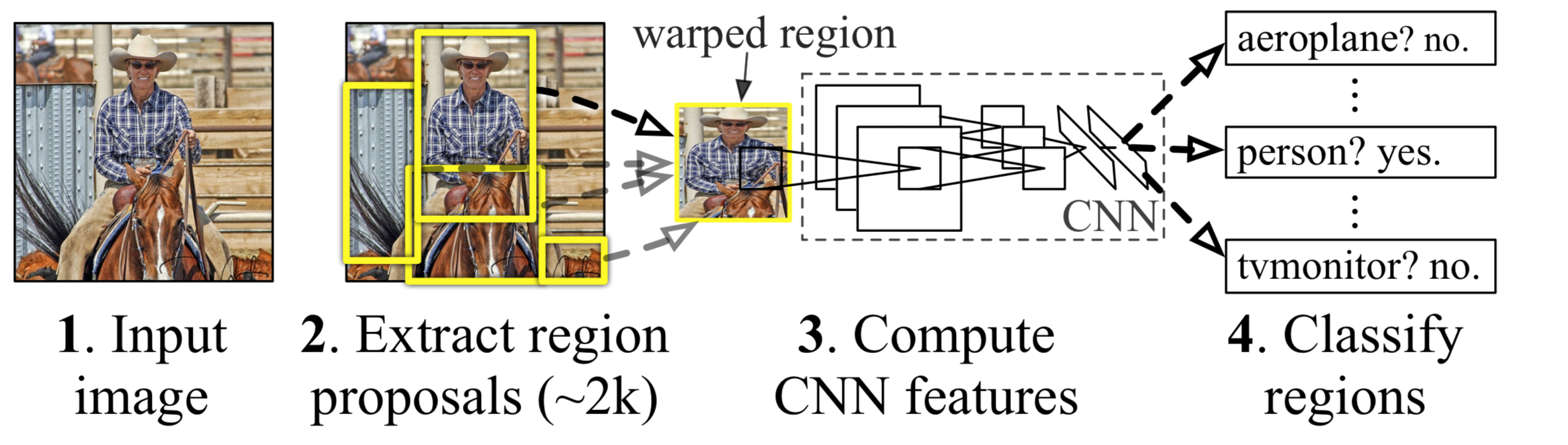
R-CNN物体检测的步骤如下:
- 输入源图,通过Selective Search算法,提取2k个左右的待选区域Regions
- 对每个Region进行Crop/Scale,缩放到同样的尺寸(为了与CNN网络最后的全联接层对齐)
- 之后对每个Region利用Pre-train的AlexNet,抽取特征(替代DPM、HOG等传统算子)(pool5 feature)[维度:4096]
- 将这些特征丢入SVM分类器(二分类)进行训练,得到的就是一个region-bbox以及对应的类别。SVM权值矩阵[4096, N],N:类别数
- 采用NMS非极大抑制算法,删除大量SS算法产生的重复区域
- 最后利用pool5 feature,训练一个线性回归模型,提高bounding box精度
创新点
从上述流程看,R-CNN与Selective Search模型差别不大,主要就是在特征提取部分,采用了2012年ILSVRC:ImageNet Large Scale Visual Recognition Chal- lenge竞赛冠军网络AlexNet,其结构如图所示:
创新点1:采用CNN提取图像特征
由于Alexnet参数众多,但PASCAL VOC任务又不像分类任务,标注难度大,数据量较少,直接训练容易造成过拟合。所以作者是对预训练的AlexNet进行fine-tuning。
具体做法是将FC-7层的1000维向量更改为21维(包括20个类及背景),并随机初始化这一全连接层的参数。训练样本的正样本来源是PASCAL VOC中人工标注的bounding box区域及类别;正样本是与bounding box计算的IoU值>=50%的Regions(这些候选Regions通过SS算法得到)。对图像进行一定程度的Crop,同时设定好batchsize、lr、SGD等超参数,进行迭代训练。需要注意这里的神经网络参数是单独训练得到的
提取上图中Pool5层的特征,作为类别的特征向量,存到硬盘中,之后再训练一个SVM二分类器,如图所示(图片来源冠军的试炼)。对于20类,即训练20个SVM二分类器。但与CNN不同的,作者通过实验,重新设置了IoU的阈值为0.3,也就是将IoU>=30%的Regions都当作正样本。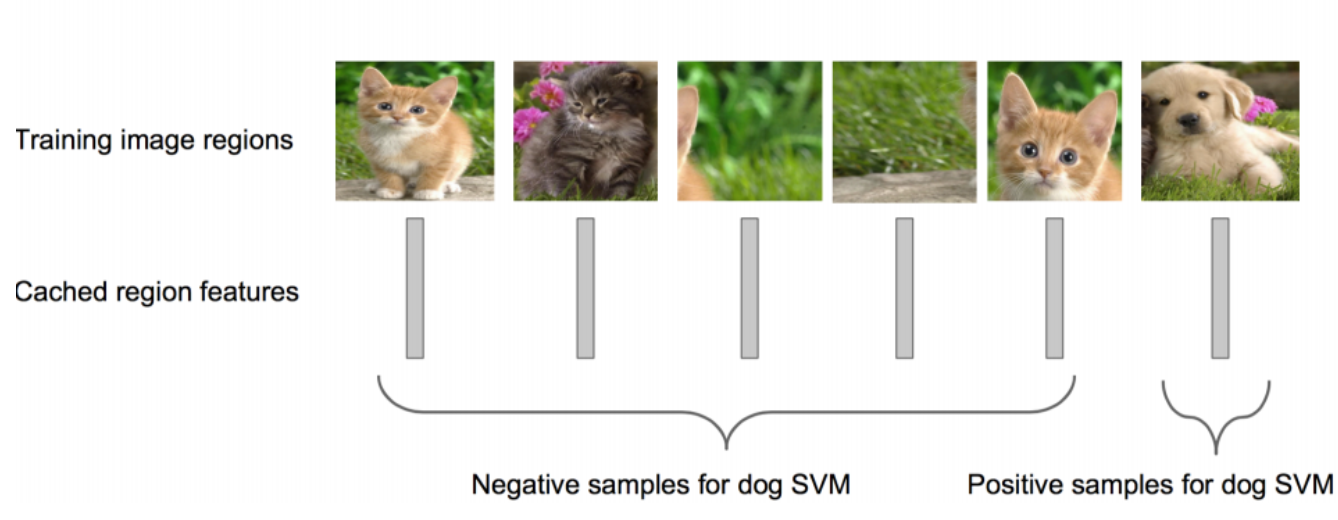
创新点2:SVM分类后采用线性回归模型精绘bounding box
训练阶段
由于SS算法对某个类的bounding box框的不够完美,所以训练一个回归模型,作者论文中采用Bounding-box regression提升了3.5个map。选取的Regions与人工标注的bounding box IoU应当>=0.6,并且仅选取IoU最大的那个作为候选Region。(此处IoU设置比较严格,作者发现如果假设函数与bounding box差距太大话,是学不到东西的)
总体目标就是对Region进行两次平移$\Delta x, \Delta y$,再进行两次缩放$S_{x}, S_{y}$。简单说就是输入pool5层的特征向量,经过4次运算后,得到更加精确的bounding box区域。论文公式如下,就是比较简单的线性回归,损失函数采用梯度下降进行优化。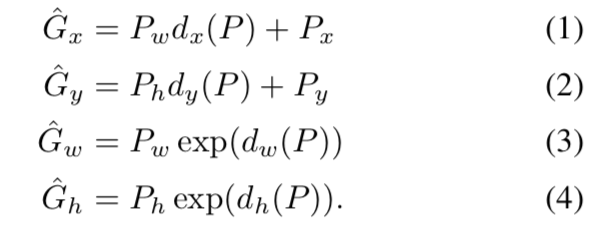
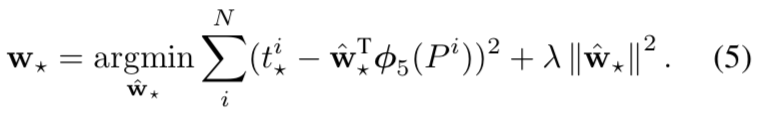
其中$d_{x}(P)$、$d_{y}(P)$为平移算术因子,$d_{w}(P)$、$d_{h}(P)$为尺度缩放算术因子。以其中的$d_{x}(P)$来说:它的实际值就是$w\phi$,为权重w乘以特征向量的形式。而其理论值是$t_{\ast }^{i}$,可以通过对(1)、(2)、(3)、(4)变换得到。最终梯度下降的优化目标便是通过最小化均方误差函数来求解该w矩阵。
测试阶段
训练阶段,我们可以采用IoU最大的Region进行训练,那test阶段呢?同一物体便可能包含大量重复的矩形框,这里作者采用的是非极大值抑制(non-maximum suppression)方法对这些区域进行筛选。NMS基于一个窗口区域被认为是最有可能表示某一个物体的时候,那么和这个窗口区域交叉面积大的proposal就可以认为不是需要的窗口区域。
具体思路为:从所有矩形框(Regions)中(不分类别)选取SVM分类器得分最高的Region,将与该Region IoU面积超过阈值的都删除。再从剩余的矩形框中选取SVM得分最高的Region,重复上述步骤,直到没有矩形框可选为止。
CNN特征提取相关:
CNN为什么选取pool5层的特征?
真实答案是如果不对模型进行fine-tuning,那么采用pool5、fc6、fc7特征训练的SVM分类器,性能是相似的;如果对模型用VOC数据fine-tuning,利用这些特征训练的分类器性能都会提升,而fc6、fc7会进一步得到更大提升,如下所示: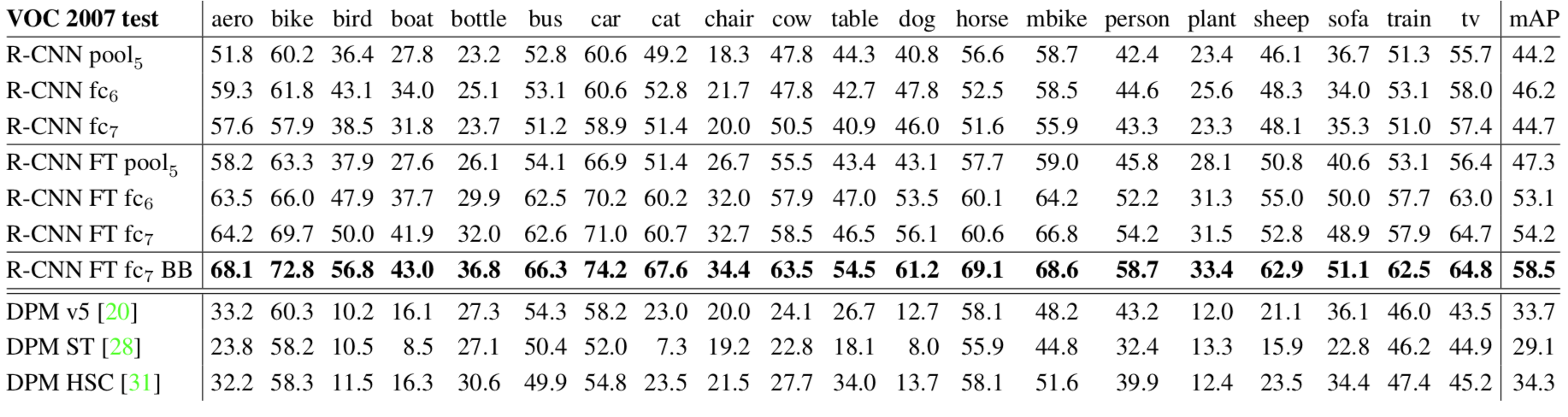
为什么不直接采用CNN端到端训练,而要接一个SVM?
确实也是可以的,但由于VOC数据集较小,如果直接端到端训练,CNN十分容易过拟合。而SVM则适合小样本训练,所以最后采用SVM进行分类。并且SVM虽然适合小样本,但作者经过调参,还是设置IoU>0.3即为正样本,比pretrain Alex Net时(IoU>0.5)的标准宽松,正样例会多一些
PS:CNN的尺度不变性:并不是一定不变,而是大概率不变。比如对于两幅size不同,内容相同的图像。假设某个卷积核提取的是图像边缘信息,那么对其Feature map进行Maxpooling操作后,都会把梯度最大值提取出来,调整Pooling的size或stride,很大概率会得到相同的map图。
RCNN存在四个明显问题:
1、多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2、针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3、每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
4、CNN、SVM、回归模型需要按顺序,进行单独训练,不能端到端训练。
Ref:
📎:Rbg大神个人主页,包含论文、slides、code等
📎:基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
📎:目标检测-RCNN系列
📎:论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
📎:RCNN学习笔记