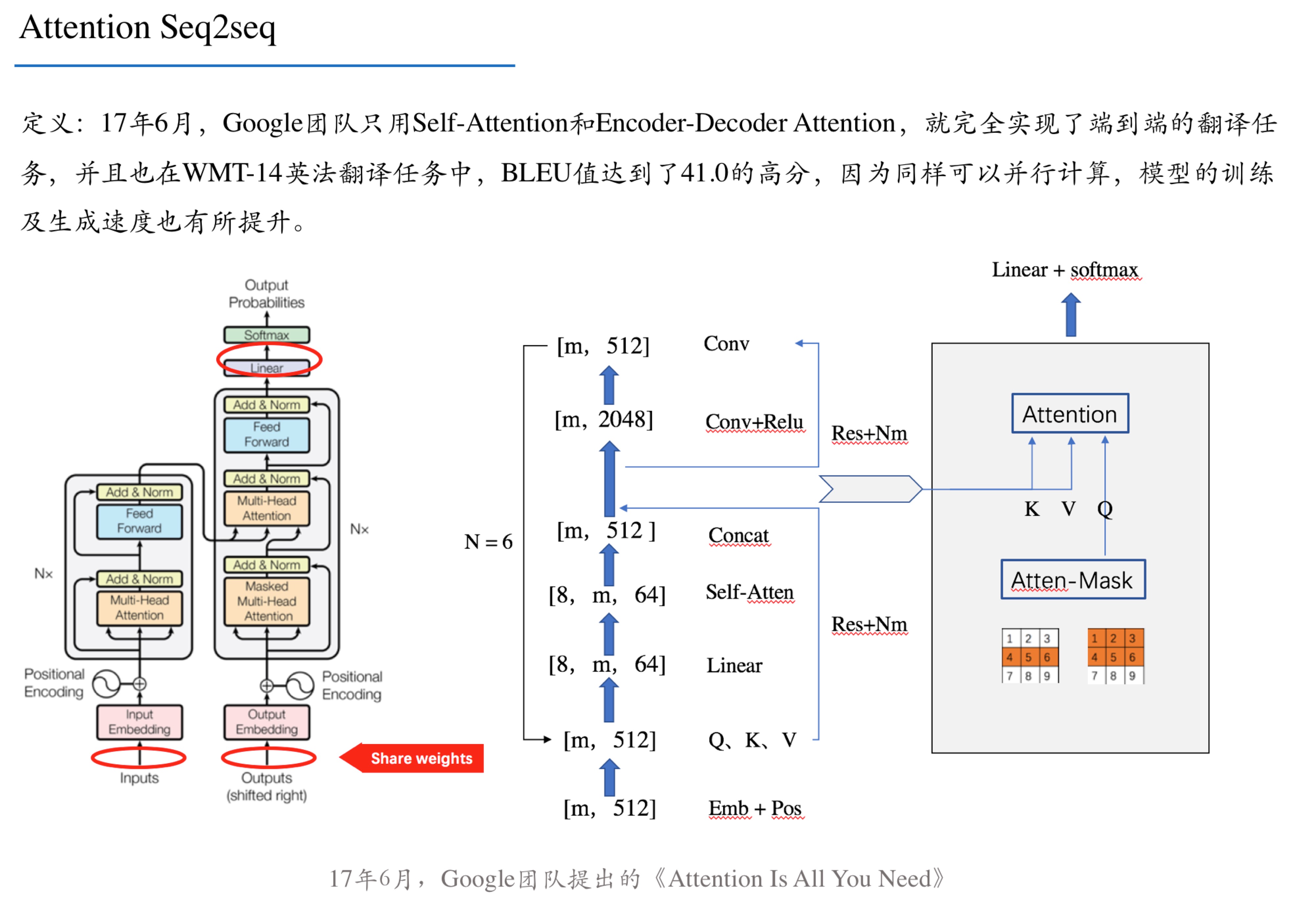
神经网络反向传播算法推导
背景
以一个单隐层神经网络简要说明反向传播算法的推导过程,需要注意的一点就是同步更新网络参数,即:在一次方向传播算法中,需要先求所有参数的偏导数,再同时更新参数。而不能以反向传播中较深层次已经更新的参数,带入偏导式子再更新浅层参数。(直观的理解就是多维度上的同步下降)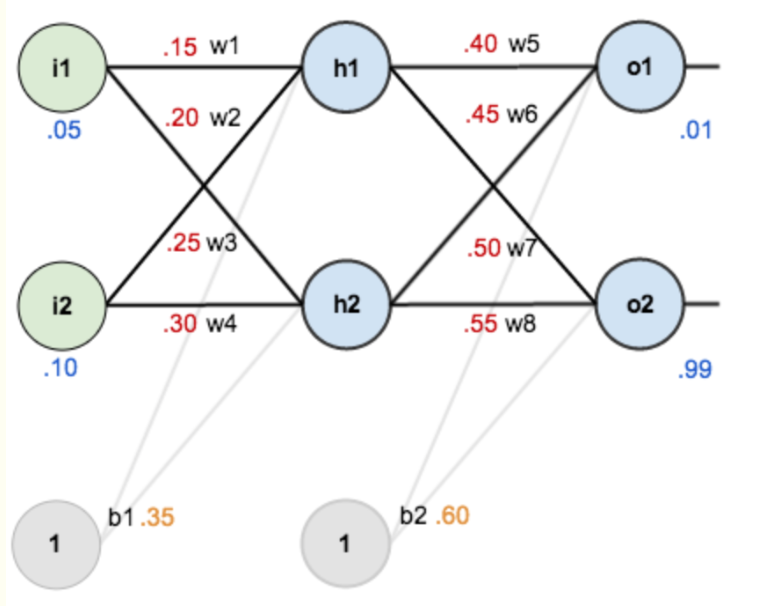
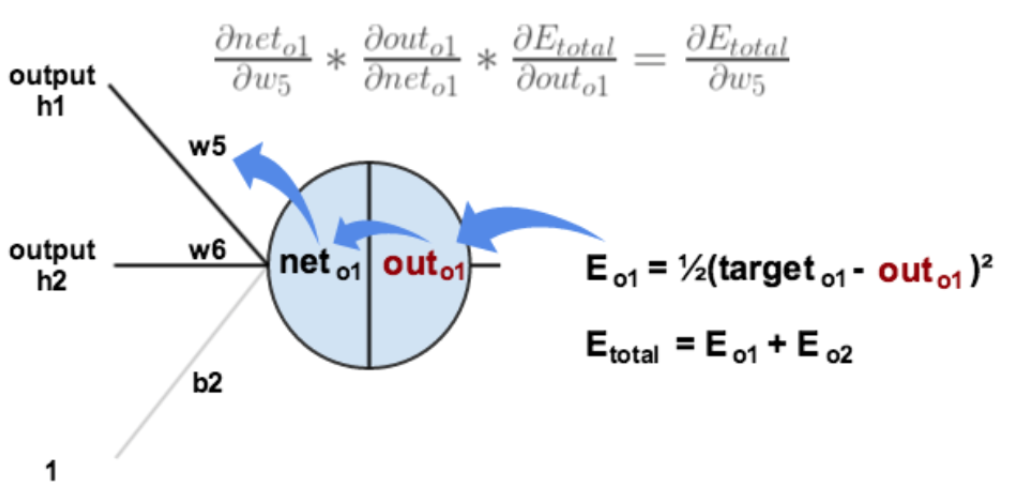 某个神经元相对于总误差的误差率:是上一层各个神经元的误差率,乘,对应到该层某个神经元的权值,再加和。之后对该神经元激活函数求导$$\delta_{h1}=\sum_{i=0}^{n}\delta_{i}w_{i}\ast out_{h1}(1-out_{h1})$$推导过程中也可以看到梯度消失的原因,每经过一个神经元,都会有
某个神经元相对于总误差的误差率:是上一层各个神经元的误差率,乘,对应到该层某个神经元的权值,再加和。之后对该神经元激活函数求导$$\delta_{h1}=\sum_{i=0}^{n}\delta_{i}w_{i}\ast out_{h1}(1-out_{h1})$$推导过程中也可以看到梯度消失的原因,每经过一个神经元,都会有sigmoid函数导数产生,用于连乘积,而该值最大值为y*(1-y)=0.25


Ubuntu下gcc/g++多版本切换
修改gcc版本时候只要修改下述软连接便可以了,首先看看系统内的gcc和g++是什么版本1
gcc --version
可以获得如下信息1
gcc version 5.4.0
查看系统内有哪些版本的gcc1
ls /usr/bin/gcc*
安装gcc1
2
3
4
5
6
7
8sudo apt-get install gcc-4.9
sudo apt-get install g++-4.9 //自动安装到/usr/bin目录下
which gcc
cd 到 gcc 目录
ll | grep gcc 显示包含gcc的软连接
sudo rm gcc
sudo ln -sf gcc-4.9 gcc
sudo ln -sf g++-4.9 g++
神经网络中的权重初始化
概念先行
正态分布(Normal distribution),又名高斯分布(Gaussian distribution),呈钟型,两头低,中间高。数学定义:随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其中期望值μ决定了其集中趋势位置;标准差σ决定了分布的幅度,σ越大,曲线越扁平,反之σ越小,曲线越瘦高。标准正态分布:当μ = 0,σ = 1时是标准正态分布。方差:sum(x-u)^2/N
一个简单的神经网络
对于z = np.sum(x*w),假如w为一个1000维的向量,服从均值为0、方差为1的正态分布,输入层x一共1000个神经元,且全为1。所以z服从的是一个均值近似为0、方差为1000的正态分布:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def run():
# z的个数
t = 20000
z_lst = np.empty(t)
x = np.ones(1000)
b = 0
for i in xrange(t):
w = np.random.randn(1000) #从标准正态分布中返回一个或多个样本值
# w = np.random.rand(1000) # 返回[0,1)之间的随机样本
#plt.hist(w, bins=50, normed=1)
#plt.show()
z = np.sum(x * w) + b
z_lst[i] = z
print 'z 均值:', np.mean(z_lst)
print 'z 方差:', np.var(z_lst)
plt.hist(z_lst, bins=50, normed=1) # hist直方图绘制函数,bins:直方图的柱数,默认为10,normed:是否进行归一化
plt.show()
if __name__ == "__main__":
run()
从图中看出:z有非常大的概率是一个远小于-1或者远大于1的数,通过激活函数(比如sigmoid)后所得到的输出非常接近0或者1。这样一来对权重的微小调整,基本不会使得隐藏层z的神经元激活值发生变化。BP时,权重更新就会非常慢。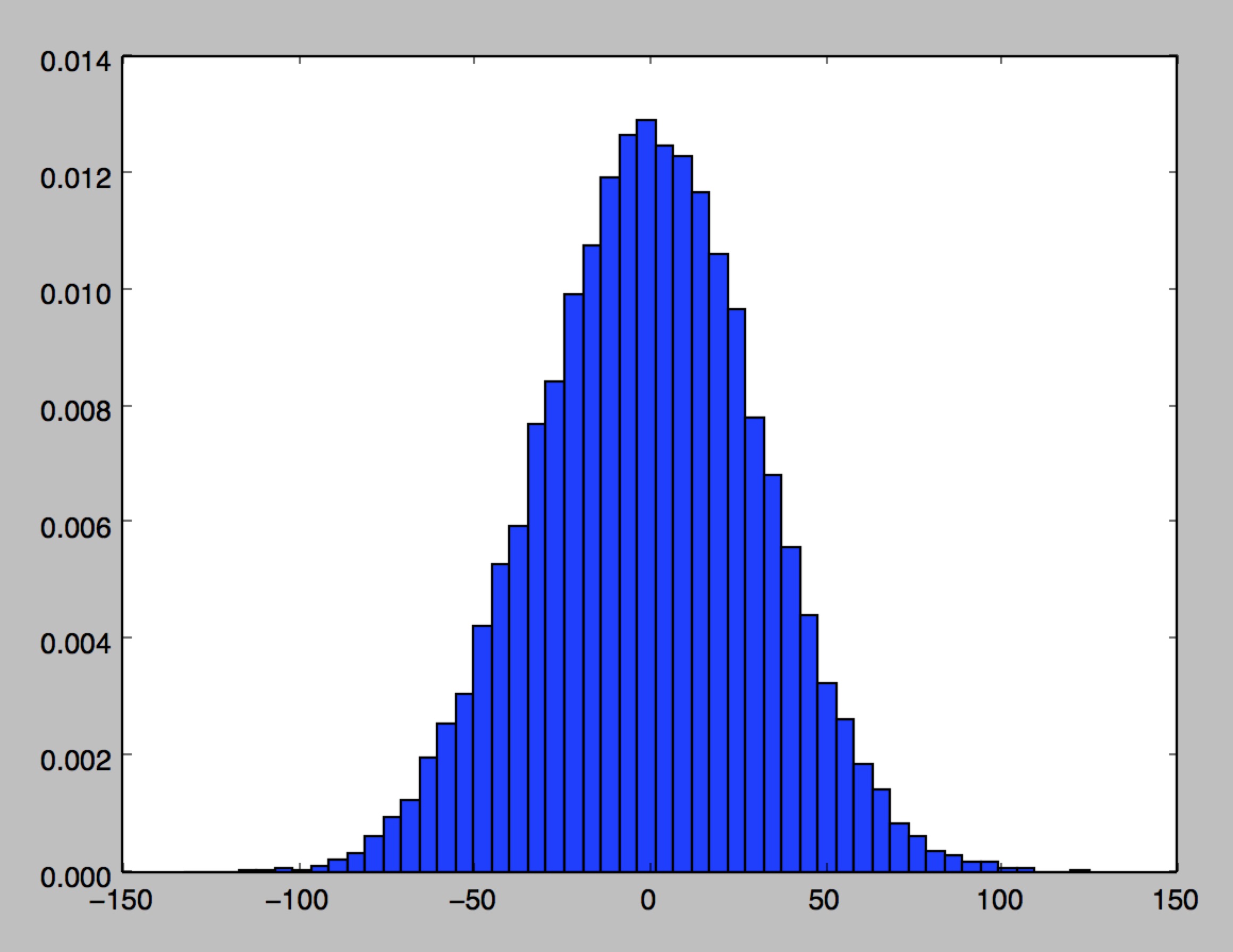
Target:那么我们的目标就是通过改变权重矩阵w的分布,使|z|尽量接近于0。经过激活函数后神经元的变化便会比较敏感。
怎样进行权重初始化
根据上述方差的计算公式:sum(x-u)^2/N ,只要x缩小sqrt(m)倍,总的方差便缩小m倍。对上述代码进行改进:1
2
3
4
5
6
7w = np.random.randn(1000)/np.sqrt(1000)
# 保持与z分布(1)图像横坐标刻度不变,使得结果更加直观
plt.xlim([-150, 150])
plt.hist(z_lst, bins=50)
plt.show()
#z 均值: 0.013468729222
#z 方差: 1.00195898464
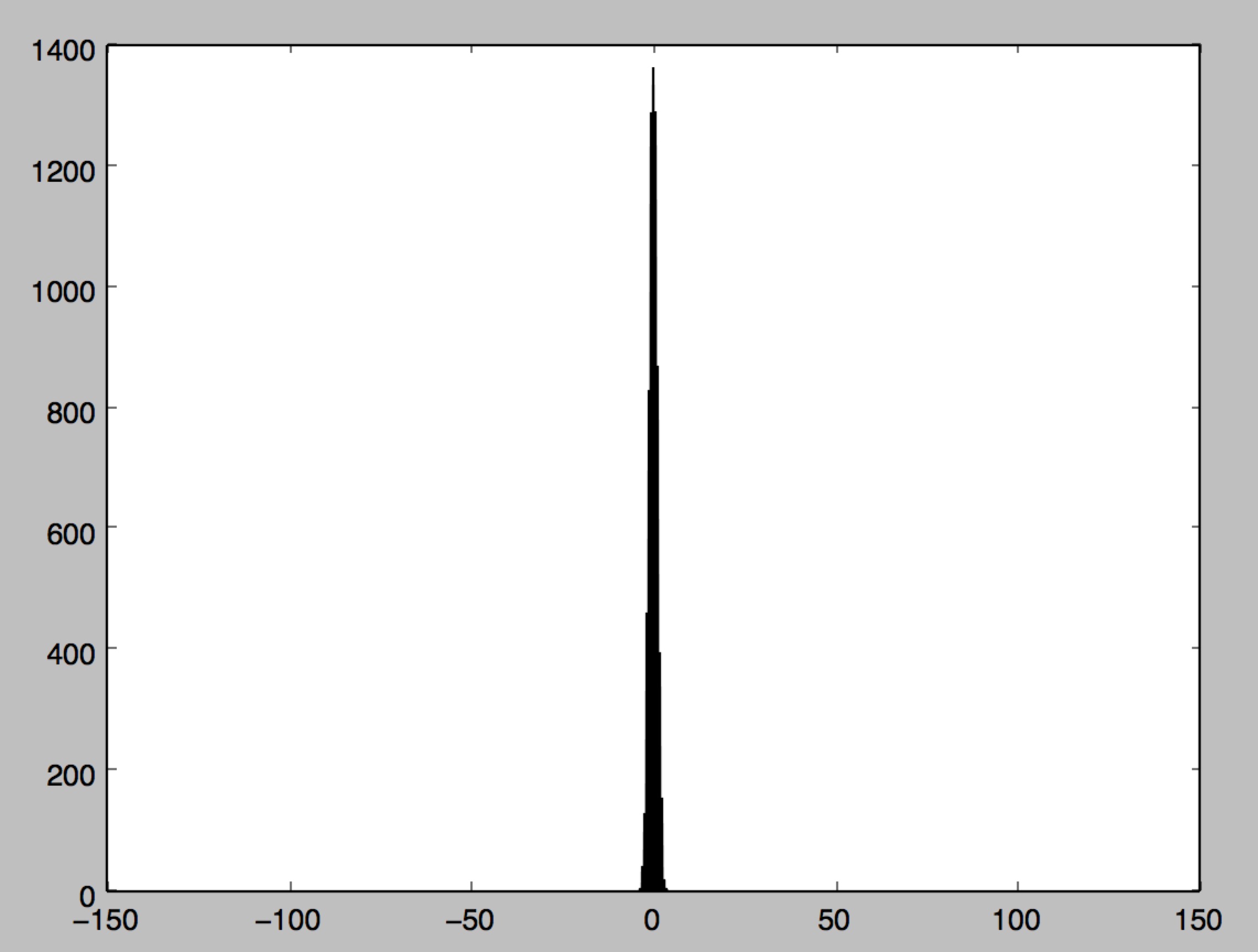
由上图可以看出,隐藏层神经元z的分布是一个比较接近于0的数,使得神经元的变化比较敏感,让BP过程能够正常进行下去。
Ref:


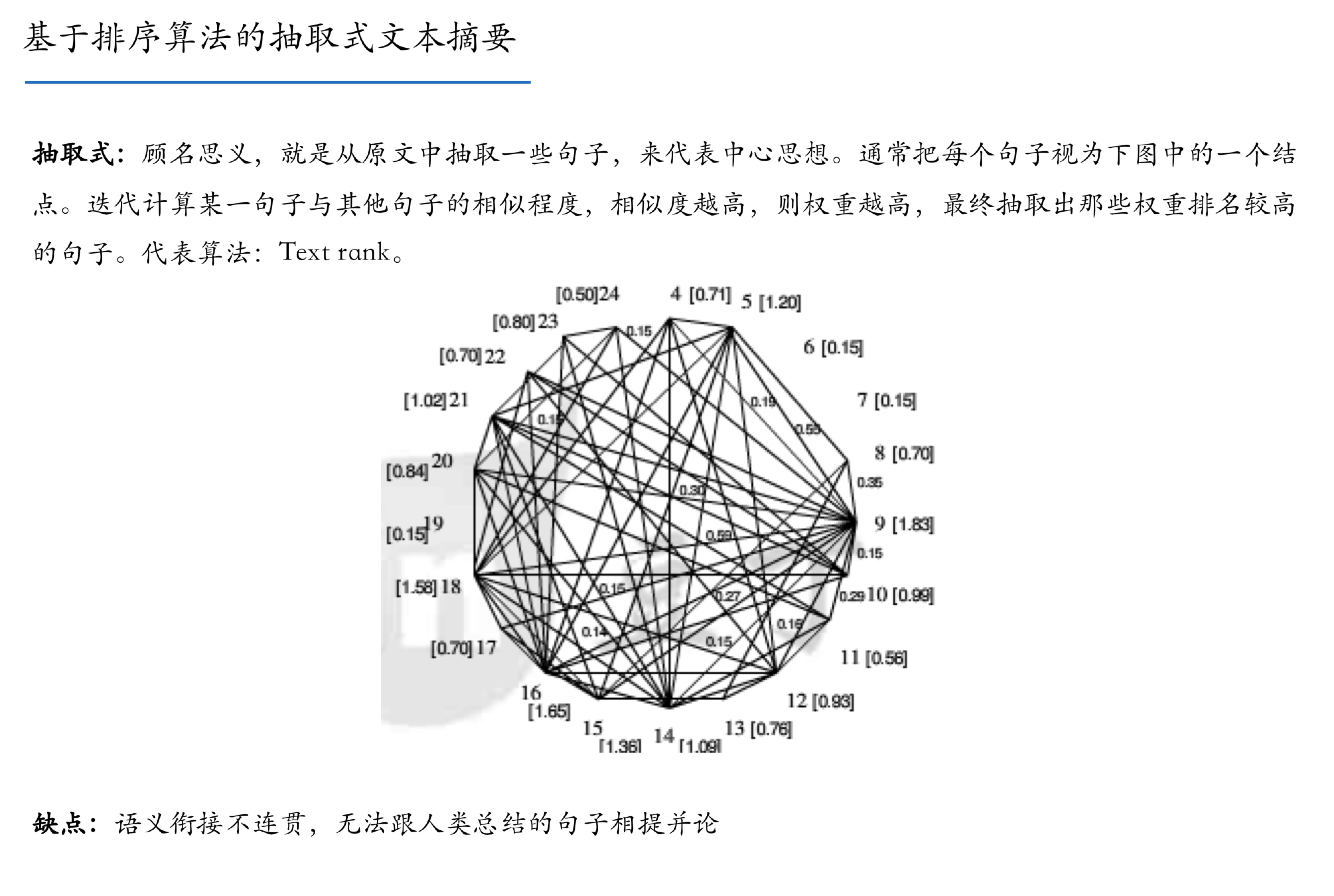
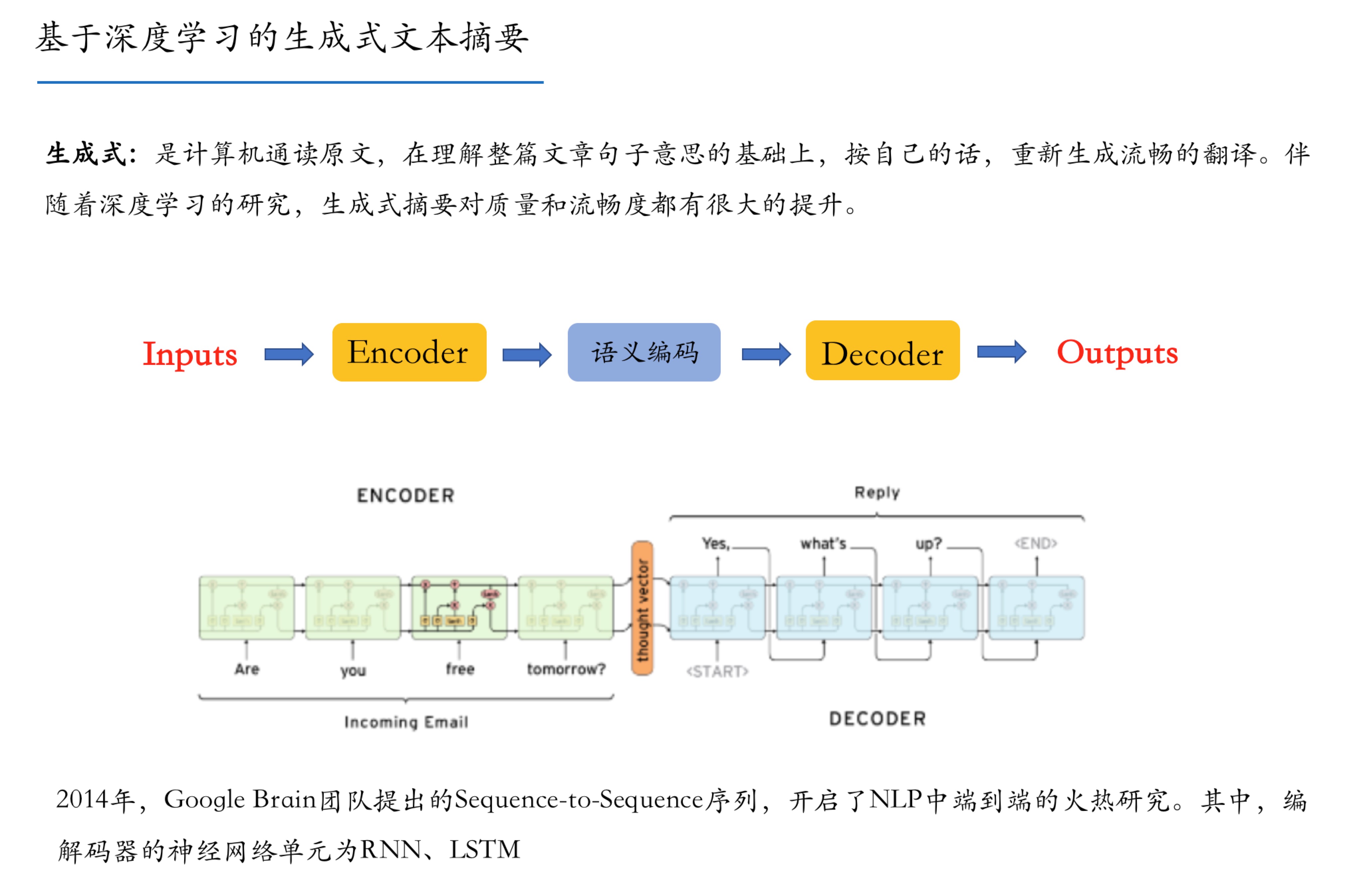
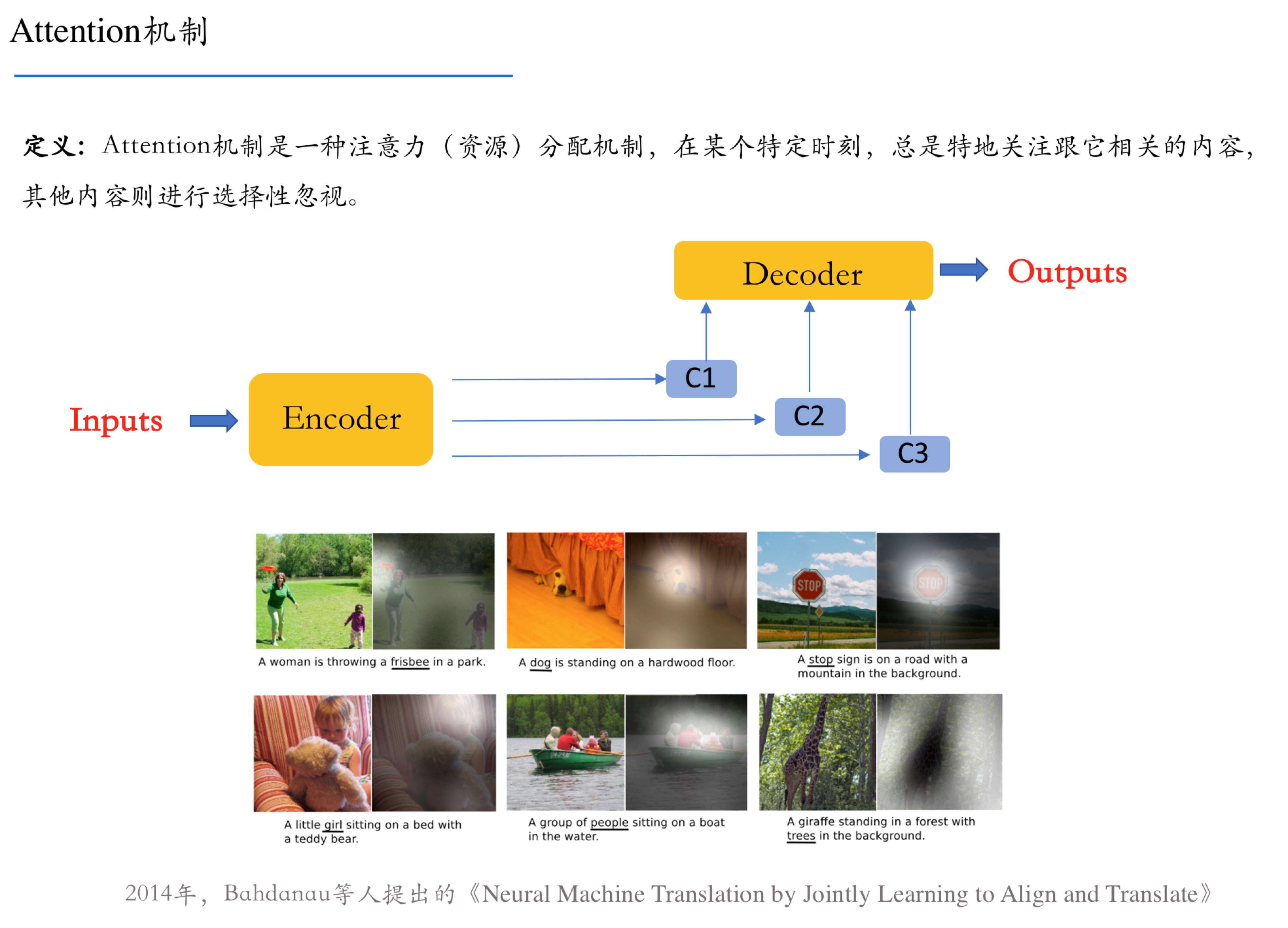
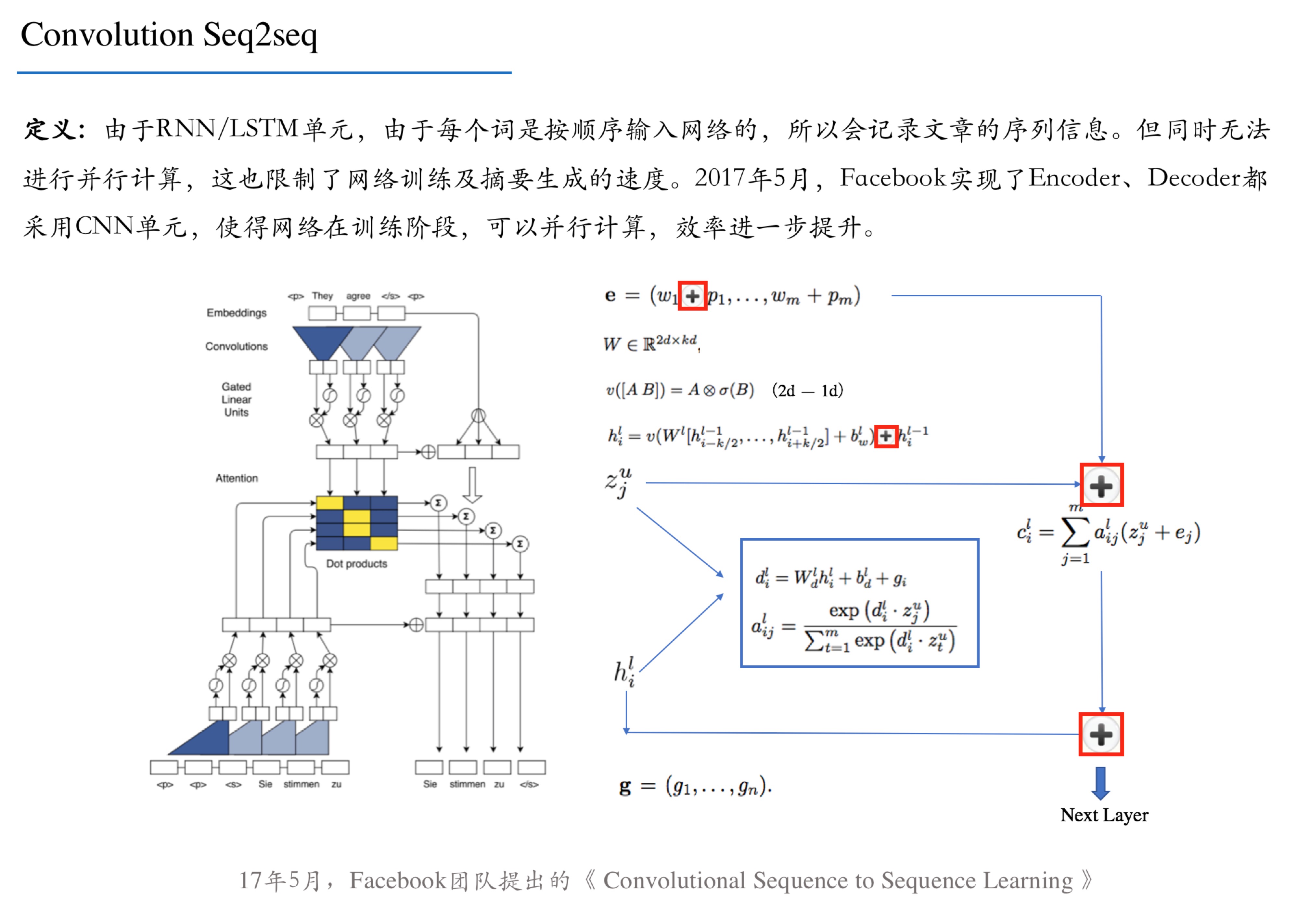
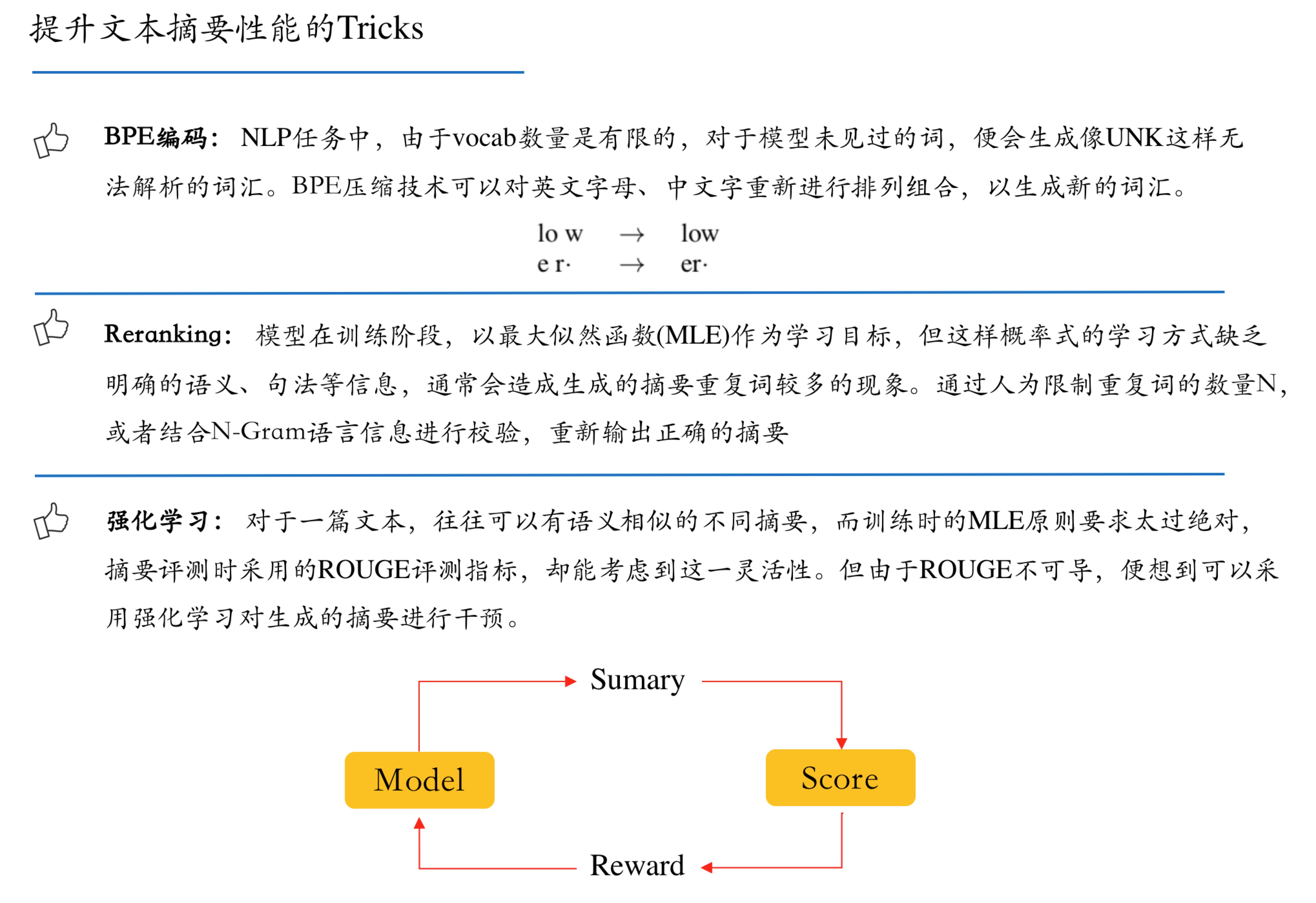

爬虫入门_文本抽取
Background
浏览器作为客户端,接收服务器返回的消息,进行解析后展示给我们。我们可以在本地修改html信息,对网页进行“整容”,要知道网页的任何信息都可以被修改,但是修改后的信息不影响服务器端,刷新后又会变成之前服务器端推送的格式。
审查元素
有了上面的认识后,怎样修改网页的html信息呢?在你想要修改页面的某个位置右击,继续点击审查,即可获得该位置的html信息。Eg:在邮箱登陆输入密码的位置点击审查元素,将password属性改为text,输入密码时将不再是小圆点的形式。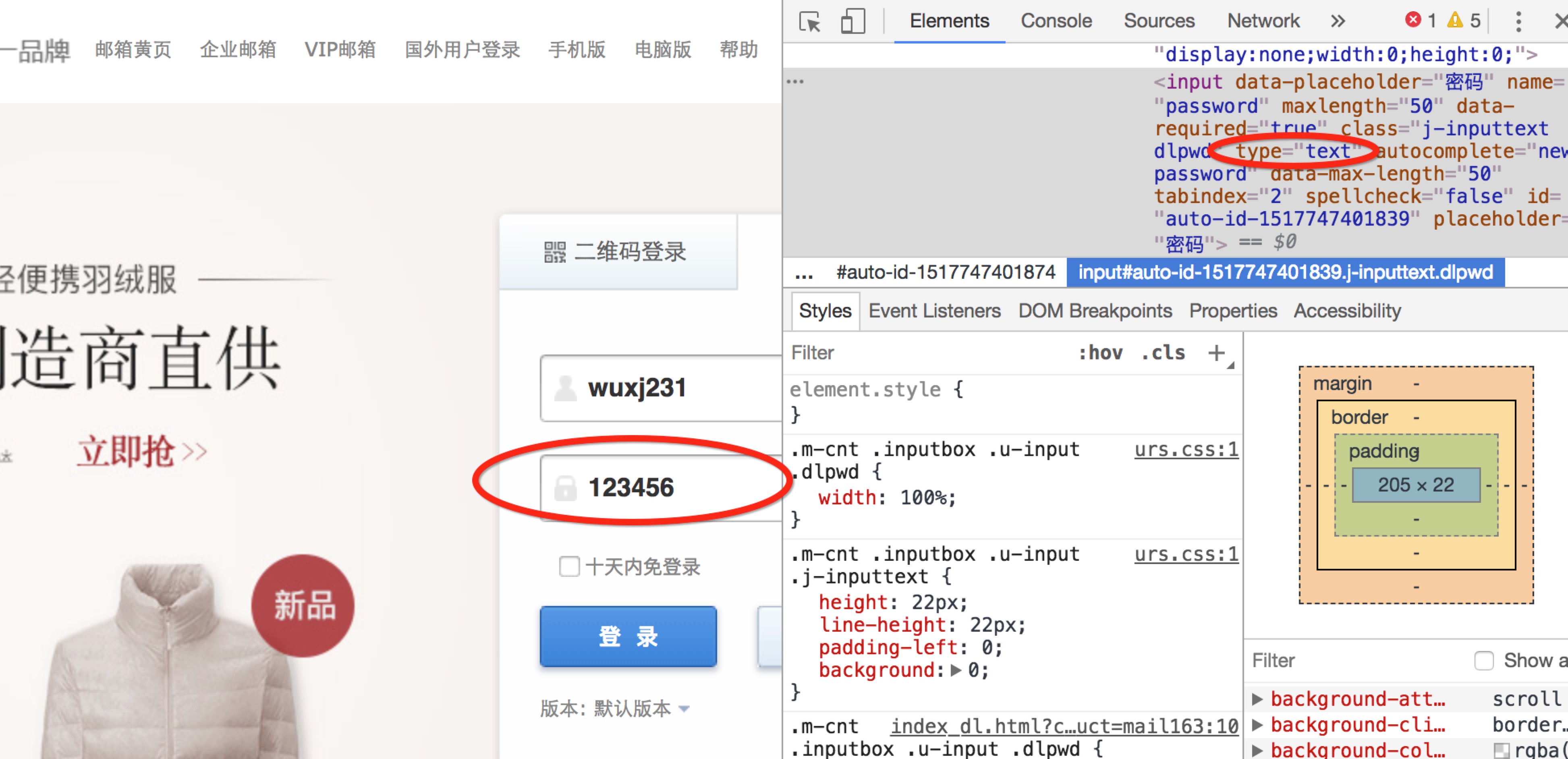
网页的全部信息都在其html语句中,接下来我们采用python中的requests模块,获取网页的html信息。
安装python http模块requests
1 | pip3 install requests |
这里简单的提取一个网络小说的html信息1
2
3
4target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
html = req.text
print(html) # 网页html内容,同右键后的网页审查内容
requests模块获取的信息为带标签(div、br…)的html信息,还需要通过下面的beautifulsoup模块,提取中我们感兴趣的段落。
安装文本提取模块Beautiful Soup
python的第三方库,用于从html、xml文件中提取数据,以树状结构的方式执行查询。并且支持正则表达式的模糊匹配。
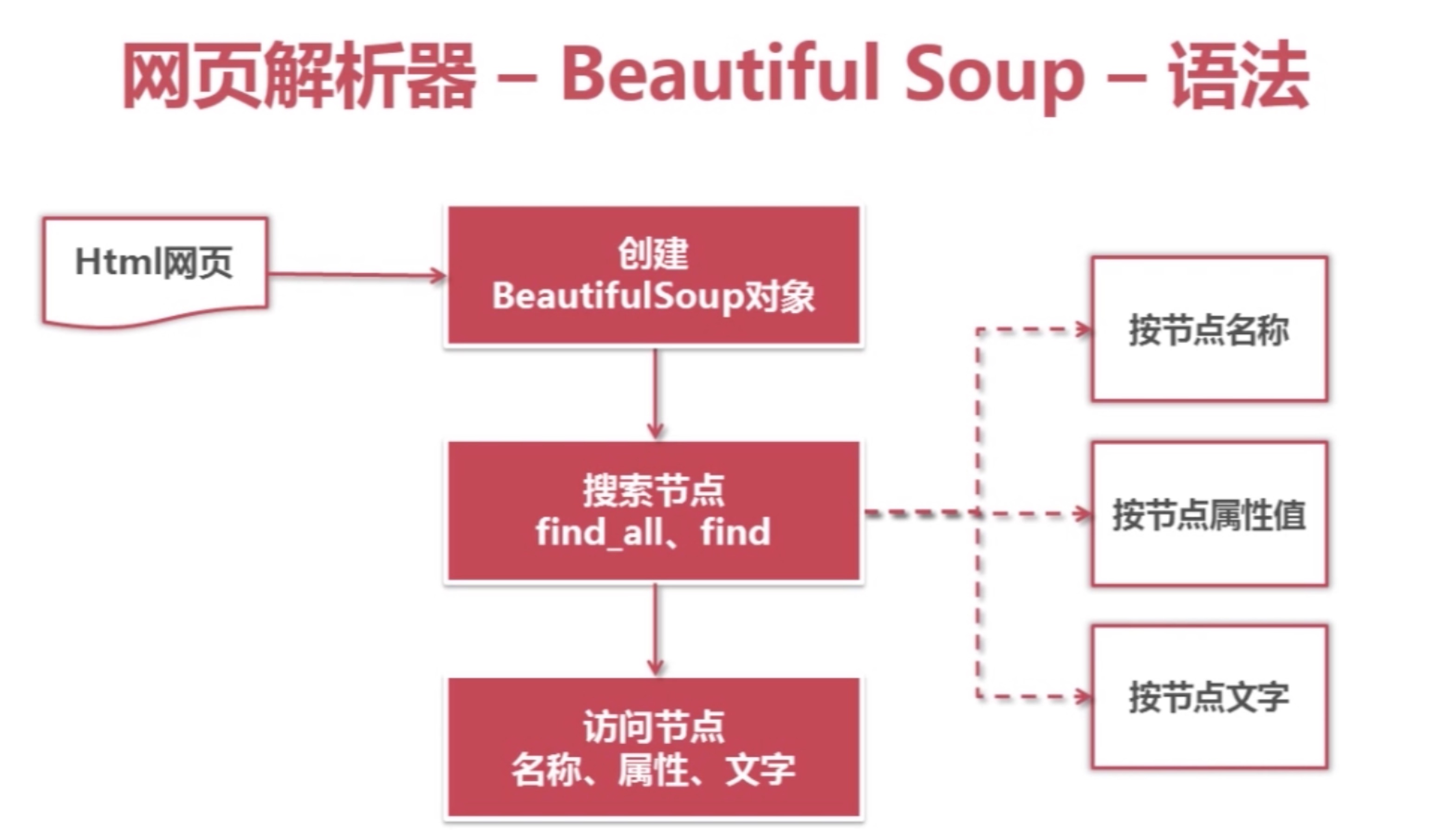
1
pip3 install beautifulsoup4
这里引用Jack-Cherish对html的解释:
“一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里”。而html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。
例如:上述例子中的div标签下存放了我们关心的正文内容。这个div标签是这样的:1
<div id="content", class="showtxt">
id和class就是div标签的属性,content和showtxt是属性值,一个属性对应一个属性值。它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。可以发现网络小说的正文部分正唯一的对应于class=”showtxt”的div标签下。1
2
3
4bf = BeautifulSoup(html) # find 一对标签:<div> </div>之间的内容
texts = bf.find_all('div', class_ = 'showtxt') # 第一个参数是获取的标签名,第二个参数class_是标签的属性
print(texts[0].text.replace('\xa0'*8,'\n\n'))
#使用text属性,提取文本内容,滤除br标签; 之后进行换行符替换及提取文本部分内容
BeautifulSoup函数处理完后,可见的是提取出了该小说完整的的正文内容。
获取每个章节的链接
章节信息都放在了class = listmain的div标签下,获取方法同上。链接和章名都放在了标签<a>、</a>之间,Eg:<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>。1
2
3
4
5
6
7
8<div class="listmain">
<dl>
<dt>《一念永恒》最新章节列表</dt>
<dd><a href="/1_1094/15932394.html">第1027章 第十道门</a></dd>
<dd><a href="/1_1094/15923072.html">第1026章 绝伦道法!</a></dd>
<dd><a href="/1_1094/15921862.html">第1025章 长生灯!</a></dd>
</dl>
</div>
通过两次调用BeautifulSoup,便可以获取一对标签<a>、</a>之间的内容。1
2
3
4
5
6
7
8req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))
完整地爬取一部小说程序整合
1 | # -*- coding:UTF-8 -*- |
Refer:
Linux操作日更贴
获取/var/www/下所有文件及文件夹的操作权限
1 | chmod 777 -R /var/www/ # 用户目录下,需要在前面再加sudo |
重装系统后清楚旧的ssh缓存协议
1 | ssh-keygen -R 192.168.1.136 |
pip、pip3升级
1 | pip/pip3 install --upgrade pip |
pip安装国外软件可能超时的解决方法
1 | pip --default-timeout=100 install --upgrade gensim |
pip安装时不存在某个xxx包,可以用下面的尝试
1 | pip install python-xxx |
pip安装Tensorflow任意指定版本
1 | pip install tensorflow-gpu=1.4.1 |
解除Ternsorboard端口占用
1 | lsof -i:6006 |
没有安装tensorboard/或python版本不对从其源码打开
1 | locate tensorboard |
安装pytorch
1 | http://tech.ifeng.com/a/20170921/44693375_0.shtml |
ubuntu teamviewe 安装
1 | apt-get purge teamviewer # 彻底移除旧的版本 |
python2.7,命令行界面输出中文字符
1 | import uniout |
查看硬盘容量及消耗
1 | sudo du -h --max-depth=1 .|sort -rh |head #查看文件夹/程序占用,由高到低排序 |
源码安装python3
1 | wget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tar.xz |
ubuntu桌面死机解决
1 | top 查看,记下PID后,q退出即可,输入 sudo kill PID |
找不到xx包相关错误…cannot find -lxxc…
先找下其他目录中是否存在需要的lib文件,有的话不用下载,直接指向就好了。找到缺失lib文件的物理位置,之后在需要的目录中建立软连接1
2
3locate libc.so
ln -s /usr/lib/x86_64-linux-gnu/libpthread.so /home/tucodec/miniconda3/compiler_compat/
rm -rf libc.7.gz 移除软连接
ffmpeg视频处理相关
# 图像合成视频 -r 20: 代表每秒20帧,注意-r需要放到-i前面,会造成时长错误
cd /home/tucodec/wuxj/ECO/results
rm test.mp4
ffmpeg -f image2 -r 5 -i %4d.png test.mp4
ffmpeg -f image2 -i im%d.png -vcodec h264 -r 25 -b 2000k test.mp4
# 视频切帧,问题是不够高清
ffmpeg -i /home/tucodec/test.mp4 -f image2 -vf fps=fps=5 /home/tucodec/results/%4d.jpg # 图片命名方式 0001.jpg
# 视频转码
ffmpeg -i test.mp4 test.avi
ffmpeg -s 832x480 -f rawvideo -i RaceHorsesC_832x480_30.yuv -f image2 ./Src/%4d.png # YUV序列转PNG
ffmpeg -s 832x480 -i RaceHorsesC_832x480_30.yuv -b:v 7776k -r 25 -vcodec h264 h264.mp4 # YUV序列转H.264视频
# 合并mp4格式视频
ffmpeg -i test.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 1.ts
ffmpeg -i test1.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 2.ts
ffmpeg -i test3.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb 3.ts
ffmpeg -i "concat:1.ts|2.ts|3.ts" -acodec copy -vcodec copy -absf aac_adtstoasc output.mp4
# 音频切割
ffmpeg -i test.mp3 -vn -acodec copy -ss 00:01:10 -t 00:00:30 output.mp3
python操作(五):函数、变量及类
变量
在 python 中,类型属于对象,变量是没有类型的,Eg:a=[1,2,3],其中[1,2,3] 是 List 类型,而变量 a 没有类型,它仅仅是一个对象的引用
函数的参数传递
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
1 | def changeme( mylist ): |
关键词参数
python中调用关键词参数,不用注意顺序,解释器会自动进行匹配1
printinfo( age=50, name="runoob" )
python遍历:
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表1
2
3
4range(5)
#range(0, 5)
list(range(5))
#[0, 1, 2, 3, 4]
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:1
2
3
4
5
6
7for i, v in enumerate(['tic', 'tac', 'toe']):
print(i, v)
'''
0 tic
1 tac
2 toe
'''
同时遍历两个或更多的序列,可以使用 zip() 组合:1
2
3
4
5questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('What is your {0}? It is {1}.'.format(q, a))
#What is your name? It is lancelot.
python类:
1 | class Complex: |
self是类的实例,不是类本身,且并不是一个关键字,也可以使用 this/toor等,但是最好还是按照约定是用self
python类方法/函数:
在类地内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
python类属性
__private_ attrs:两个下划线开头,声明该属性为私有,不能在类地外部被使用或直接访问,但可以通过调用类的公有函数访问。在类内部的方法中使用时 self.__private_attrs。
python操作(四):IO编程/调用shell语句
python调用shell语句
1 | ''' |
上面调用shell语句的方式,跟python语句是独立进行的,也就是说无法进行变量的交互
采用下面的语句可以实现在python中操作文件/文件夹
1 | import os |
python操作(三):Unicode编码
Background
中文字符一般都是编码为Unicode存储在计算机中的,然而表现形式却大不相同,有的程序喜欢给你输出中文,有的喜欢输出乱码,Eg:'\xe5\xbc\xa0\xe4\xbf\x8a'。python2/3中的字符串编码,就有这样的问题,在此进行梳理,有备无患。
ASCII、Unicode和UTF-8关系
由于1个字节(byte) == 8位(bit),所以1字节最多可以表示256个字符。美国人在发明计算机时候,英文字母(大小写共64个),加上一些标点符号,256个字符安全够用。这个编码就被称为ASCII编码。比如’A’对应ASCII码表中的65,’z’对应122。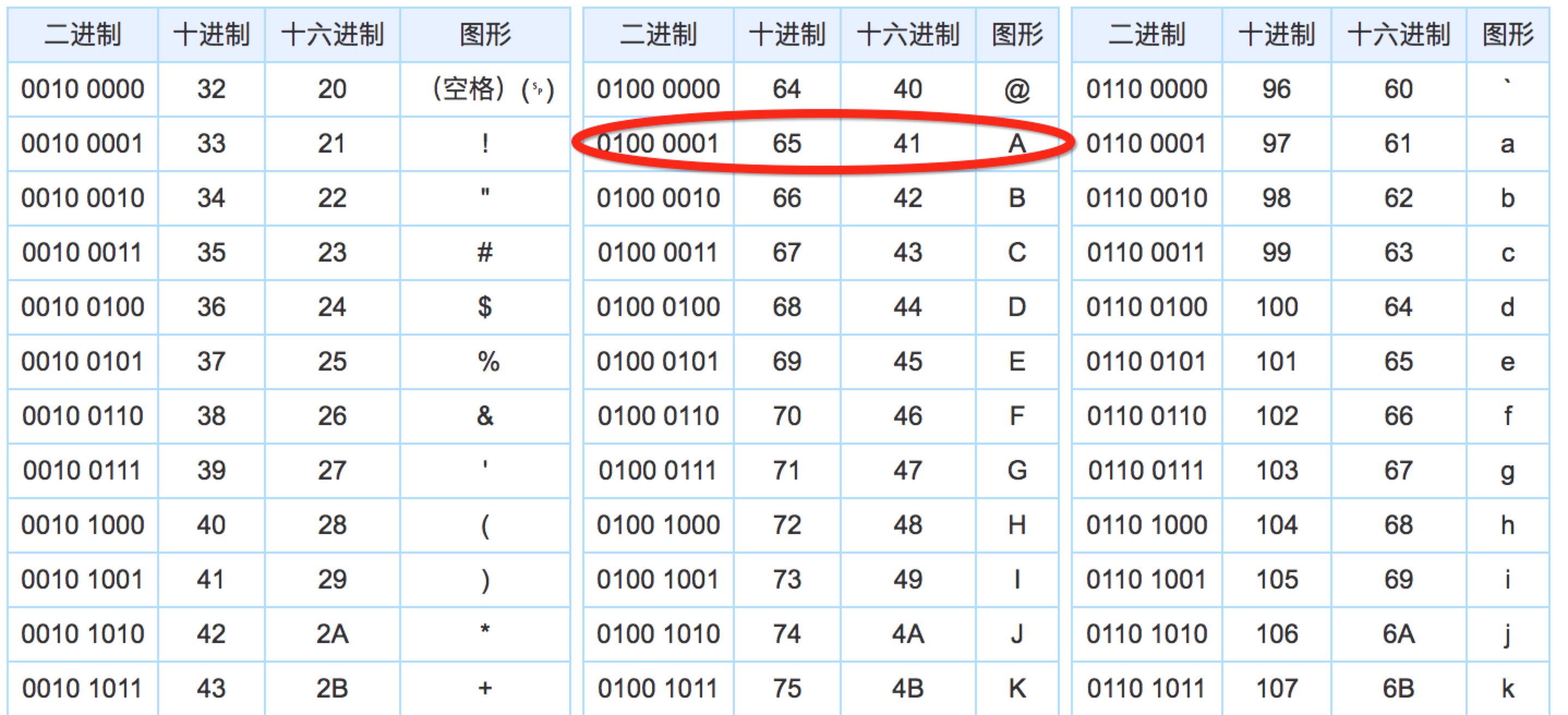
但我们的中文博大精深,256个字符显然不能覆盖全部字符,所以中国制定了2字节的GB2312编码(GBK是GB2312的扩充,包含的中文字符更多)。无独有偶,各个国家都制定了自己的规则把本国的文字编写进去。为了统一各个语言之间的编码,Unicode应运而生,具体来说,ASCII用1个字节表示字符,Unicode用2个字节,对于一些特殊符号,甚至使用4个字节。ASCII编码的’A’用Unicode编码,只需要在前面补0就可以了。
虽然乱码消失,但却造成了新的问题:如果你写的文本基本上都是英语,那用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF-8编码再次被发明,它是对Unicode编码的再编码,对于常用的英文编码为1字节,汉子通常为3字节。如果需要传输、保存的文本含有大量应为,这样的编码可以减少带宽,减少硬盘成本。如下所示:
python2
1 | Python 2.7.10 (default, Jul 15 2017, 17:16:57) |
python3
1 | Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 08:49:46) |
小结
- python2中字符串有str和unicode两种类型,str有各种编码区别(UTF-8、GBK等),unicode是没有编码的标准形式。unicode通过encode转化成str,str通过decode转化成unicode。
- python3中字符串有str和bytes两种类型,字符串str与python2中unicode类似是标准形式,bytes类似python2中的str有各种编码区别。所以在python3中查看某个字符串的编码序列,只能先将str编码为一定形式的bytes数据,然后再输出
1 | Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 08:49:46) |