背景
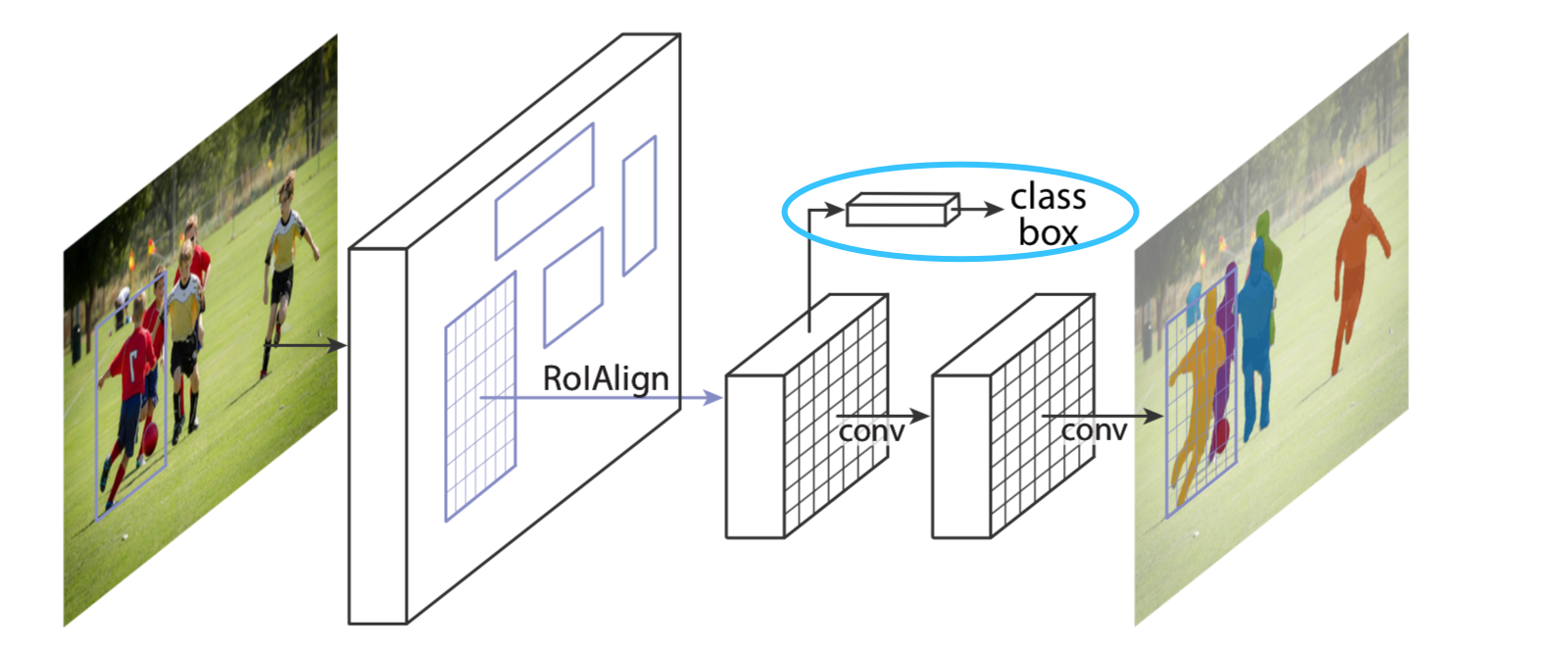
Mask R-CNN是基于Faster R-CNN网络打造的,从下面的图就可以直观看出他们的区别
1、首先蓝框中为Faster R-CNN中的全连接网络;
2、左边[7, 7]的conv模块为ROI Pooling/Align的结果;
3、右边[7, 7]的conv模块为新增的用于训练Mask分支的全卷积网络FCN(这里是pixel to pixel的映射,所以需要用到FCN)
ROI Align
借用网上的一张图,Faster R-CNN中会造成两次量化误差,一次是RPN网络产生Region Proposal时,对ground bounding box的量化,另外一次是Pooling到[7, 7]的feature map时的量化,均是因为像素没有浮点数,强行四舍五入造成的。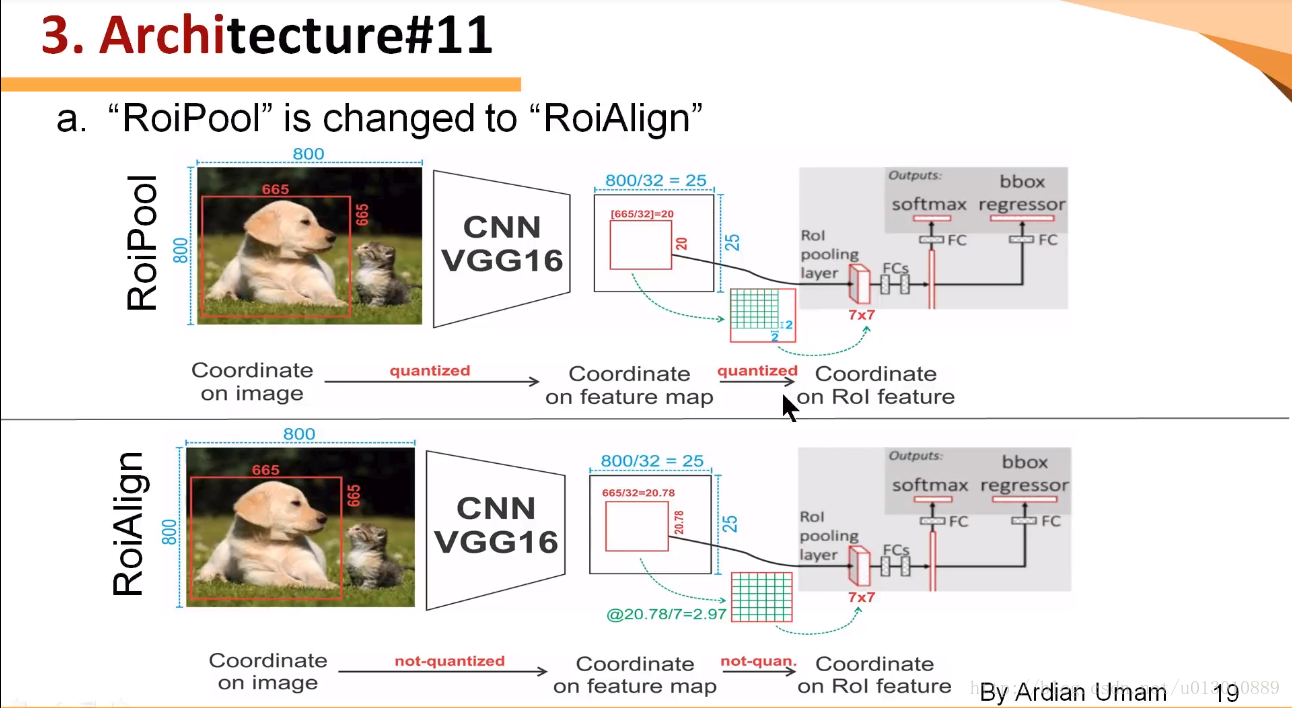 但是由于feature map大小是原图的1/32,半个像素误差就会导致原图16个像素的差别,这在绘制Mask这种Pixel量级的任务时,会造成很大的误差。
但是由于feature map大小是原图的1/32,半个像素误差就会导致原图16个像素的差别,这在绘制Mask这种Pixel量级的任务时,会造成很大的误差。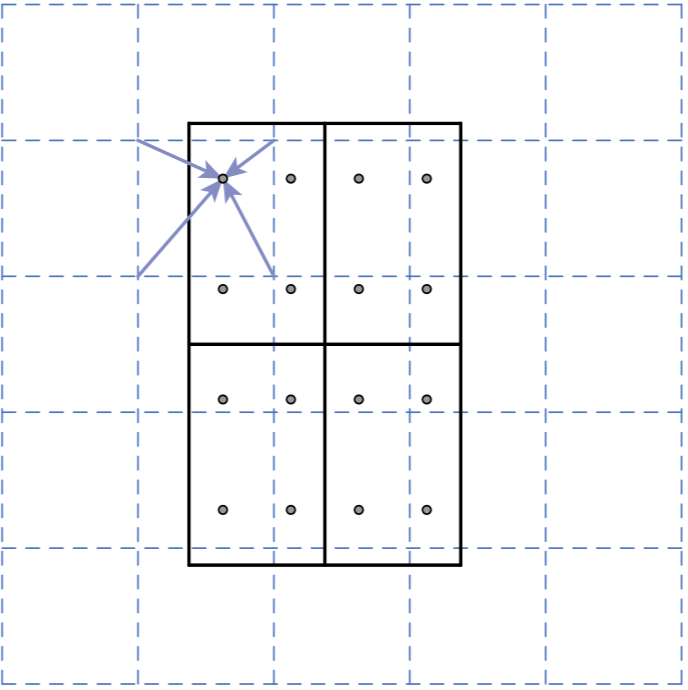 如上图所示,作者在Mask R-CNN中对RPN、Pooling层都保留浮点数值,并且对Pooling后map中的每个像素点,分别采用双线性插值,本质就是在X/Y两个方向做线性插值(算法解析),来计算4个虚拟点的像素值。之后再进行max/average pooling,池化后的结果即为最终pooling后map的像素值。
如上图所示,作者在Mask R-CNN中对RPN、Pooling层都保留浮点数值,并且对Pooling后map中的每个像素点,分别采用双线性插值,本质就是在X/Y两个方向做线性插值(算法解析),来计算4个虚拟点的像素值。之后再进行max/average pooling,池化后的结果即为最终pooling后map的像素值。
Ref:
📎:详解 ROI Align 的基本原理和实现细节
📎:目标检测:Mask R-CNN 论文阅读
📎:Mask RCNN-论文简记