SPP Net
R-CNN的进阶版Fast R-CNN可以说是在RCNN的基础上采纳了SPP Net方法,使得性能进一步提高。所以有必要先了解下何凯明提出的SPP Net。SPP:Spatial Pyramid Pooling(空间金字塔池化)。他有两个显著的特点:
创新点1:实现CNN的多尺度输入,忽略图片尺寸的影响
为了实现全联接层可以正确匹配pooling层后的维度,R-CNN中笔者先对Region proposal Crop到某一固定维度,但这样会造成一定的图像失真。有没有不Crop图像从而实现维度匹配的方法呢?一是调整最后的pooling层维度,二是调节全联接层的结构,使它接受任意维度特征。后一种方法是全卷积网络(FCN),本文是采用的是前一种,即SPP:空间金字塔pooling。
SPP的具体实现方式:假设与全联接层匹配的最后一个pooling层,输出维度应当是$[2\ast 2]$。而此时ROI区域的大小为$[5\ast 7]$(Region proposal在该论文中又称为ROI区域)。那么此时pooling核的size应当为$[\frac{5}{2} \ast \frac{7}{2}]$,才能使该ROI区域pooling后,得到匹配的size。但核的size不能为小数啊,所以采用理论size做间隔,最后向下取整得到每个pooling核的size。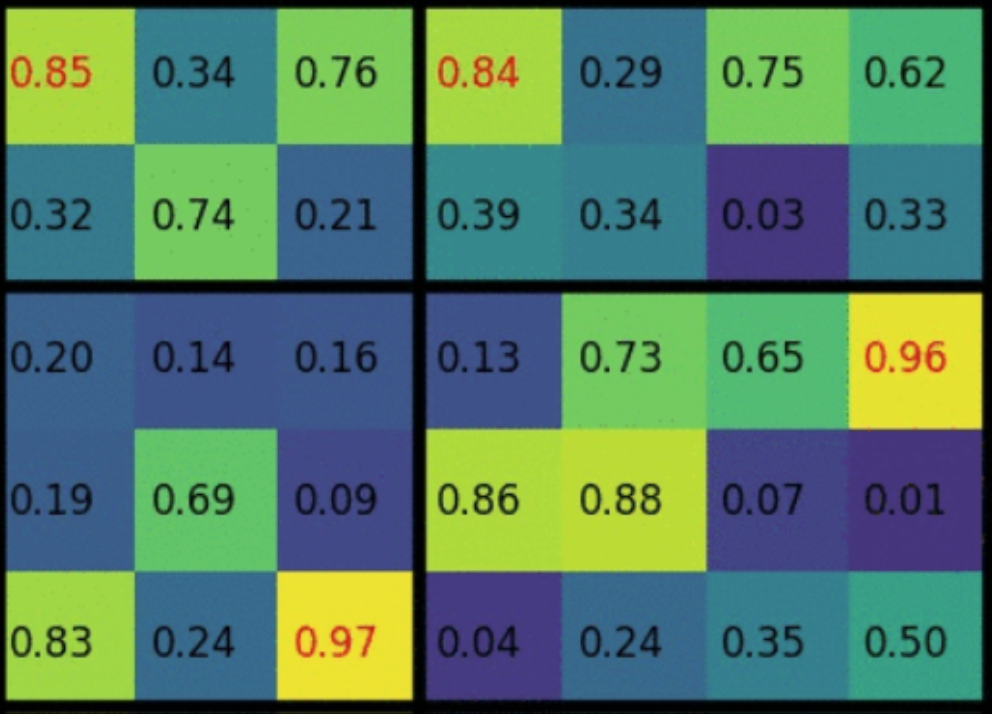
如上图所示:H方向以2.5为间隔$[0, 2.5, 5]$,W方向以3.5取间隔$[0, 3.5, 7]$。最后每个pooling核起始点坐标为H:$[2, 5]$,W:$[3, 7]$。更广泛地,我们用$[h, w]$代表ROI区域的高和宽,$[H, W]$代表希望pooling后得到的高和宽。那么每个网格动态调整后的大小为$[\frac{h}{H} \ast \frac{w}{W}]$。
ps:假如ROI区域$[2,2]$小于pooling后目标维度$[3,3]$怎么办?一样的处理方式,每个pooling核起始点坐标为H:$[1,1,2]$,W:$[[1,1,2]$,类似于图像的最近邻法上采样(其实这样取整的方式引入了很多误差,后面的Mask RCNN中将ROI pooling层修改为ROI Align)
小结:SPP说到底就是计算一个比例关系,以动态调整pooling核的大小,实在是非常简单
创新点2:只对原图提取一次卷积特征
RCNN中,一张图片Region proposal的数量为2K个,其中存在大量的重复区域。而用CNN提取这些Region,显然是非常复杂的一件事儿。SPP Net中的做法是对整张图像用CNN仅提取一次特征,feature map一般计算到最后一个pooling层。接着再根据相应的缩放比例,对源图的Regions进行一一映射,找到其在feature map的位置即可。该算法看似简单,但对于regions的特征提取,速度提升约146倍。
Fast R-CNN
Fast R-CNN是在SPP Net基础上做的进一步改进,作者把SVM分类器换成Softmax,和CNN整合成一个网络,同时把bounding box regression也整合进网络中,三层联动调节参数,从而带来了效果的进一步提升。Fast RCNN架构如图所示: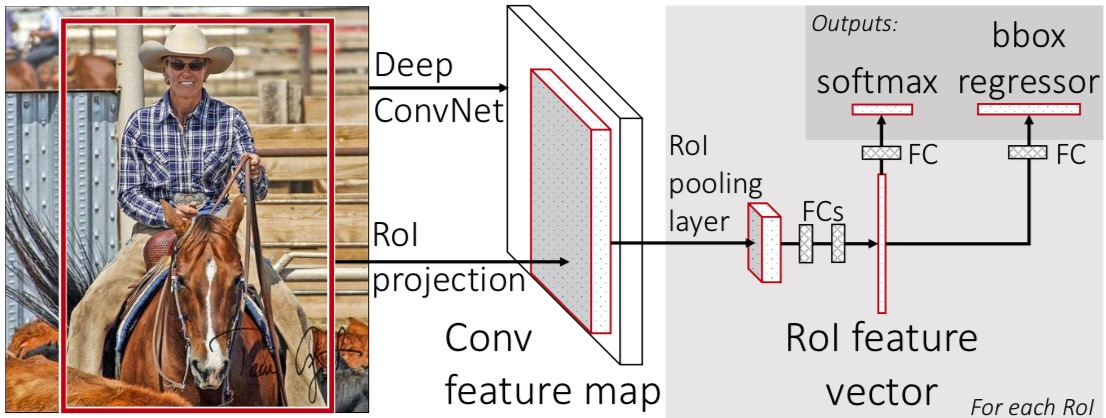
该网络是典型的多任务学习,低层的卷积层参数共享(采用VGG16提取特征),高层分别训练分类及回归网络。多任务学习一般用在task具有一定相似度的情境下。网络总的损失函数是两部分乘系数相加$L = L_{cls} + \lambda \times L_{loc}$,对于$L_{cls} $采用softmax-loss损失函数,对于Bounding box regression采用特殊的一种损失函数,如下:
$$L_{loc}(t^{u}, v) = \sum_{i = {x,y,w,h}}smooth_{L1}(t_{i}^{u}-v_{i})$$
$$if \left | x \right |<1 \qquad smooth_{L1}(x) =0.5x^{2} \qquad || \qquad Otherwise \qquad smooth_{L1}(x) = \left | x \right | -1 $$
这部分没有深究,其中$t_{i}, v_{i}$分别代表Region proposal和ground truth的坐标。Fast R-CNN的联合损失函数可以直接进行反向传播,从而达到端到端训练的目的。
Ref:
📎:Fast RCNN
📎:论文笔记:Fast(er) RCNN
📎:一箭N雕:多任务深度学习实战
📎:RCNN,Fast RCNN,Faster RCNN 总结