Background
浏览器作为客户端,接收服务器返回的消息,进行解析后展示给我们。我们可以在本地修改html信息,对网页进行“整容”,要知道网页的任何信息都可以被修改,但是修改后的信息不影响服务器端,刷新后又会变成之前服务器端推送的格式。
审查元素
有了上面的认识后,怎样修改网页的html信息呢?在你想要修改页面的某个位置右击,继续点击审查,即可获得该位置的html信息。Eg:在邮箱登陆输入密码的位置点击审查元素,将password属性改为text,输入密码时将不再是小圆点的形式。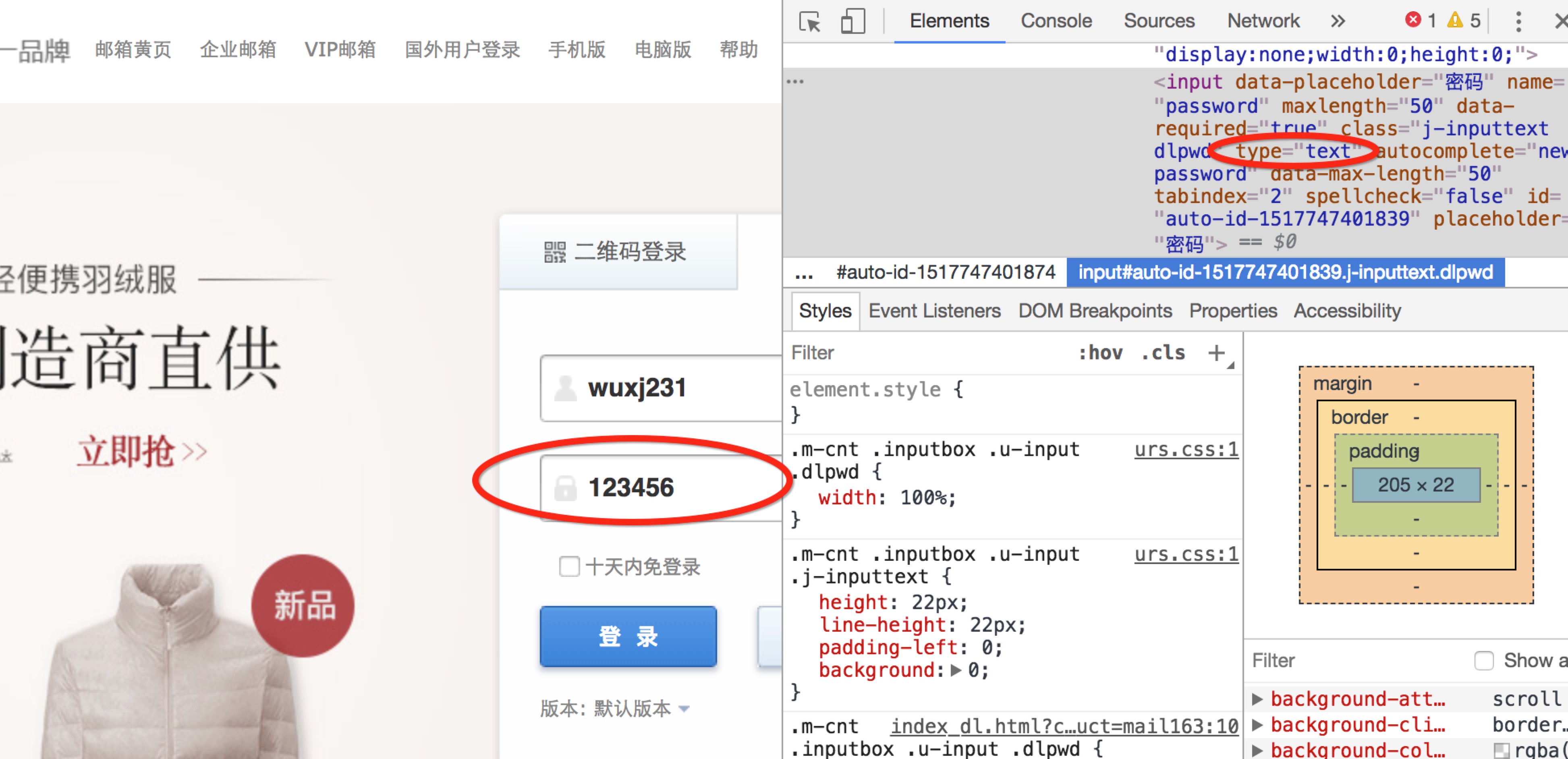
网页的全部信息都在其html语句中,接下来我们采用python中的requests模块,获取网页的html信息。
安装python http模块requests
1 | pip3 install requests |
这里简单的提取一个网络小说的html信息1
2
3
4target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
html = req.text
print(html) # 网页html内容,同右键后的网页审查内容
requests模块获取的信息为带标签(div、br…)的html信息,还需要通过下面的beautifulsoup模块,提取中我们感兴趣的段落。
安装文本提取模块Beautiful Soup
python的第三方库,用于从html、xml文件中提取数据,以树状结构的方式执行查询。并且支持正则表达式的模糊匹配。
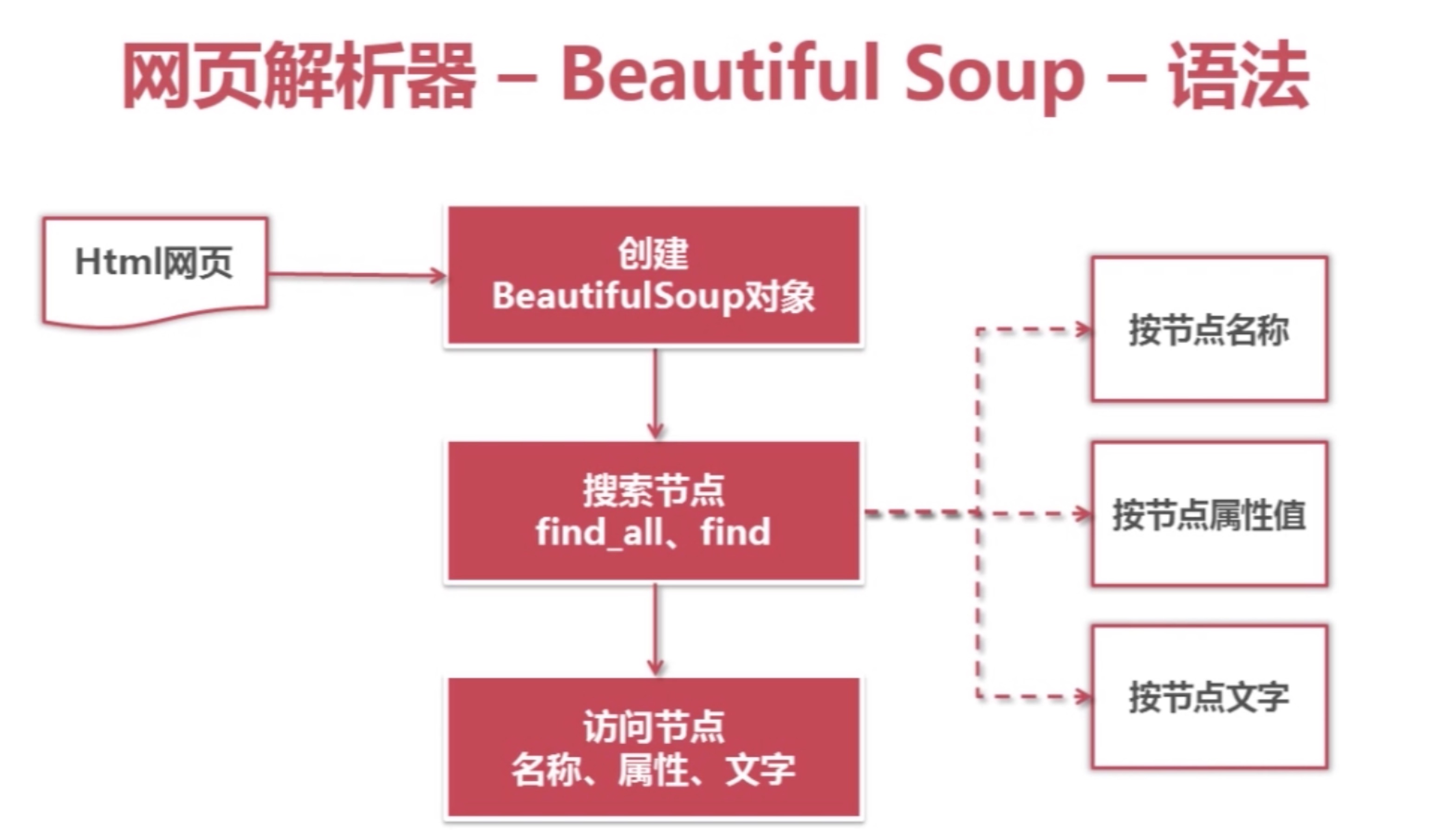
1
pip3 install beautifulsoup4
这里引用Jack-Cherish对html的解释:
“一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里”。而html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。
例如:上述例子中的div标签下存放了我们关心的正文内容。这个div标签是这样的:1
<div id="content", class="showtxt">
id和class就是div标签的属性,content和showtxt是属性值,一个属性对应一个属性值。它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。可以发现网络小说的正文部分正唯一的对应于class=”showtxt”的div标签下。1
2
3
4bf = BeautifulSoup(html) # find 一对标签:<div> </div>之间的内容
texts = bf.find_all('div', class_ = 'showtxt') # 第一个参数是获取的标签名,第二个参数class_是标签的属性
print(texts[0].text.replace('\xa0'*8,'\n\n'))
#使用text属性,提取文本内容,滤除br标签; 之后进行换行符替换及提取文本部分内容
BeautifulSoup函数处理完后,可见的是提取出了该小说完整的的正文内容。
获取每个章节的链接
章节信息都放在了class = listmain的div标签下,获取方法同上。链接和章名都放在了标签<a>、</a>之间,Eg:<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>。1
2
3
4
5
6
7
8<div class="listmain">
<dl>
<dt>《一念永恒》最新章节列表</dt>
<dd><a href="/1_1094/15932394.html">第1027章 第十道门</a></dd>
<dd><a href="/1_1094/15923072.html">第1026章 绝伦道法!</a></dd>
<dd><a href="/1_1094/15921862.html">第1025章 长生灯!</a></dd>
</dl>
</div>
通过两次调用BeautifulSoup,便可以获取一对标签<a>、</a>之间的内容。1
2
3
4
5
6
7
8req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))
完整地爬取一部小说程序整合
1 | # -*- coding:UTF-8 -*- |