Background
中文字符一般都是编码为Unicode存储在计算机中的,然而表现形式却大不相同,有的程序喜欢给你输出中文,有的喜欢输出乱码,Eg:'\xe5\xbc\xa0\xe4\xbf\x8a'。python2/3中的字符串编码,就有这样的问题,在此进行梳理,有备无患。
ASCII、Unicode和UTF-8关系
由于1个字节(byte) == 8位(bit),所以1字节最多可以表示256个字符。美国人在发明计算机时候,英文字母(大小写共64个),加上一些标点符号,256个字符安全够用。这个编码就被称为ASCII编码。比如’A’对应ASCII码表中的65,’z’对应122。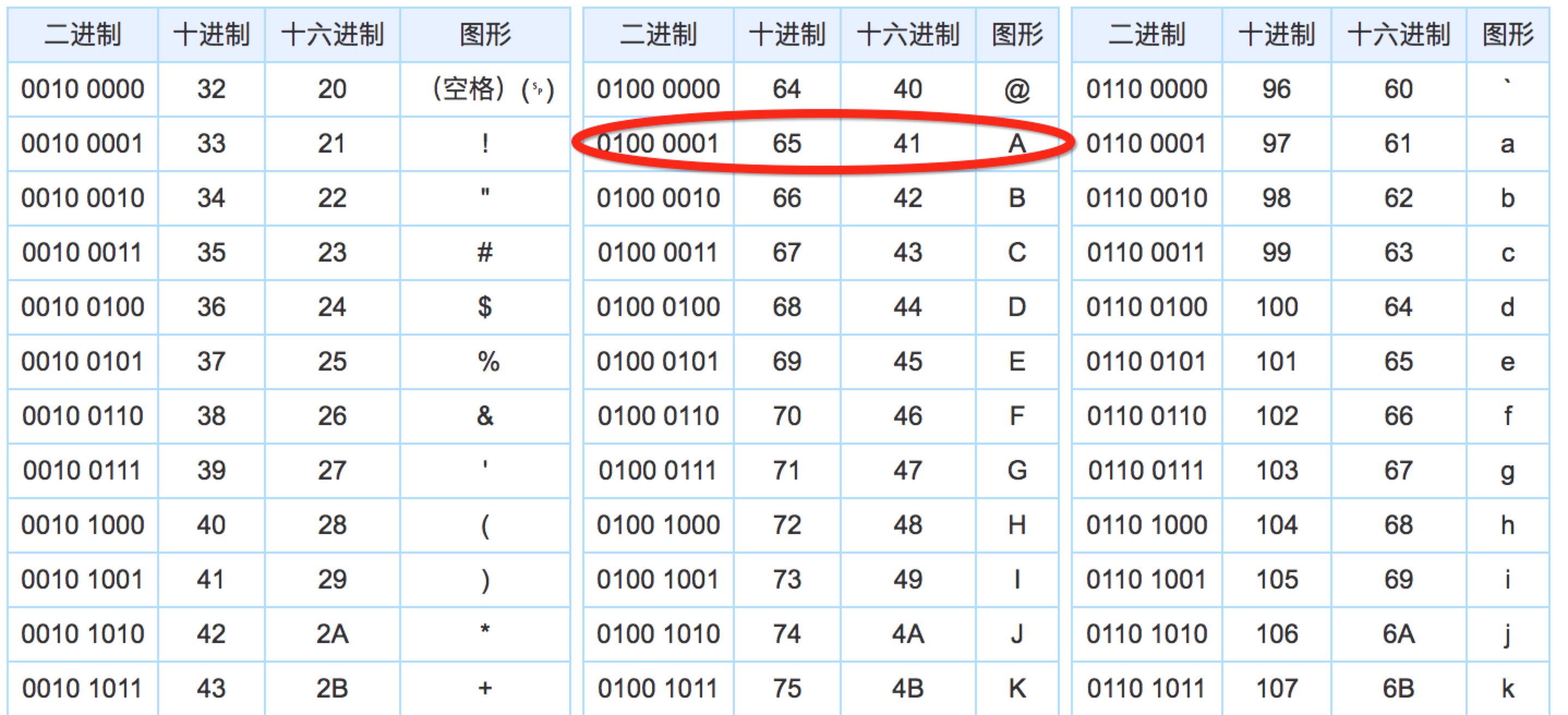
但我们的中文博大精深,256个字符显然不能覆盖全部字符,所以中国制定了2字节的GB2312编码(GBK是GB2312的扩充,包含的中文字符更多)。无独有偶,各个国家都制定了自己的规则把本国的文字编写进去。为了统一各个语言之间的编码,Unicode应运而生,具体来说,ASCII用1个字节表示字符,Unicode用2个字节,对于一些特殊符号,甚至使用4个字节。ASCII编码的’A’用Unicode编码,只需要在前面补0就可以了。
虽然乱码消失,但却造成了新的问题:如果你写的文本基本上都是英语,那用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF-8编码再次被发明,它是对Unicode编码的再编码,对于常用的英文编码为1字节,汉子通常为3字节。如果需要传输、保存的文本含有大量应为,这样的编码可以减少带宽,减少硬盘成本。如下所示:
python2
1 | Python 2.7.10 (default, Jul 15 2017, 17:16:57) |
python3
1 | Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 08:49:46) |
小结
- python2中字符串有str和unicode两种类型,str有各种编码区别(UTF-8、GBK等),unicode是没有编码的标准形式。unicode通过encode转化成str,str通过decode转化成unicode。
- python3中字符串有str和bytes两种类型,字符串str与python2中unicode类似是标准形式,bytes类似python2中的str有各种编码区别。所以在python3中查看某个字符串的编码序列,只能先将str编码为一定形式的bytes数据,然后再输出
1 | Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 08:49:46) |