1. 词汇表示Background
one-hot编码
文本、字符串看似简单,其实是经过几千万年的演化,人类抽象出的非常高维、稀疏的特征。拿汉语来说,词汇数量约为几十万。如果采用ont-hot形式编码,一个词语的维度就将占据几十万维。训练时候往往是上亿个词,这便会造成巨大的维数灾难。
Word2vec
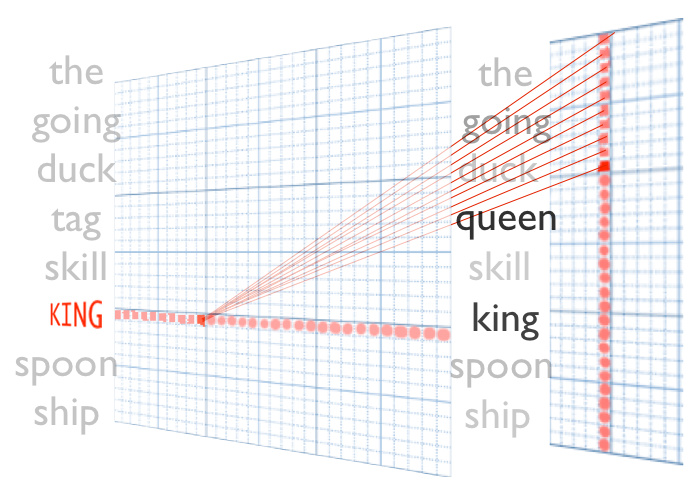
而Word2vec(中文名:词向量/词嵌入),可以自由控制词汇的维度,常用的维度数一般为256、512…1024维。相对于one-hot编码词汇的离散表示,Word2vec是一种词汇的分布式表示(distribution representation)。比如某个词汇被以维度为[1,256]的一维向量表示,如果是一个包含100个词的句子,那么这句话被表示为[100,256]。写到这里,其实便可以意识到这跟图像用像素矩阵来表示是非常类似的。
Word2vec特点
因为Deep learning的优势是从低维特征中自动学习、提取高维特征,词的分布式表示便可以充当词汇的低维特征表示,所以目前像文本分类、机器翻译、摘要等NLP任务,都使用Word2vec表示的词汇来作为模型的input。使得NLP领域也因为Deep learning 取得了不错的进步。如下是搜索“爱因斯坦”的相近词汇
----跟“爱因斯坦”相近的词------
宇宙学 0.808888375759
牛顿 0.800362348557
相对论 0.791419327259
定律 0.76971578598
拓扑 0.764759659767
但因为Word2vec衡量的是文本共现程度,只能反映两者经常在相近的上下文环境中出现。所以它并不是真正意义上的语义表示,只能说一种近似,或者说其中存在很多的语义误差,并不像像素可以精确表示一副图像的底层信息。笔者认为这也是造成NLP领域并没有像图像、语音识别领域取得非常长足进步的重要原因。
由于词汇背后丰富的语义信息,并不能通过Word2vec完全表示,最近也有学者尝试用更细的粒度来表示词汇。清华大学的刘知远老师利用HowNet:一种用最基本的、不宜再被分割的最小语义单位来表示的语义体系,跟Word2vec相结合,也获得了一些可以展望的成果《在深度学习时代用HowNet搞事情》
Word2vec重要组件
Word2vec(以下简称词向量),虽然作为概率语言模型的input,但其实是训练语言模型产生的中间结果。
- 两个语言模型:
- Skip-gram:根据当前词语wt,预测上下文的词语(wt-1、wt+1)的模型。
- CBOW:Continuous Bag-of-Words Model的缩写,与Skip-gram正好相反
- 优化Softmax归一化:
- Hierarchical Softmax:采用哈夫曼树思想分层求取Target概率
- Negative sampling:softmax时仅采样少量词汇作映射
2. Word2vec重要组件详解
神经网络语言模型简化
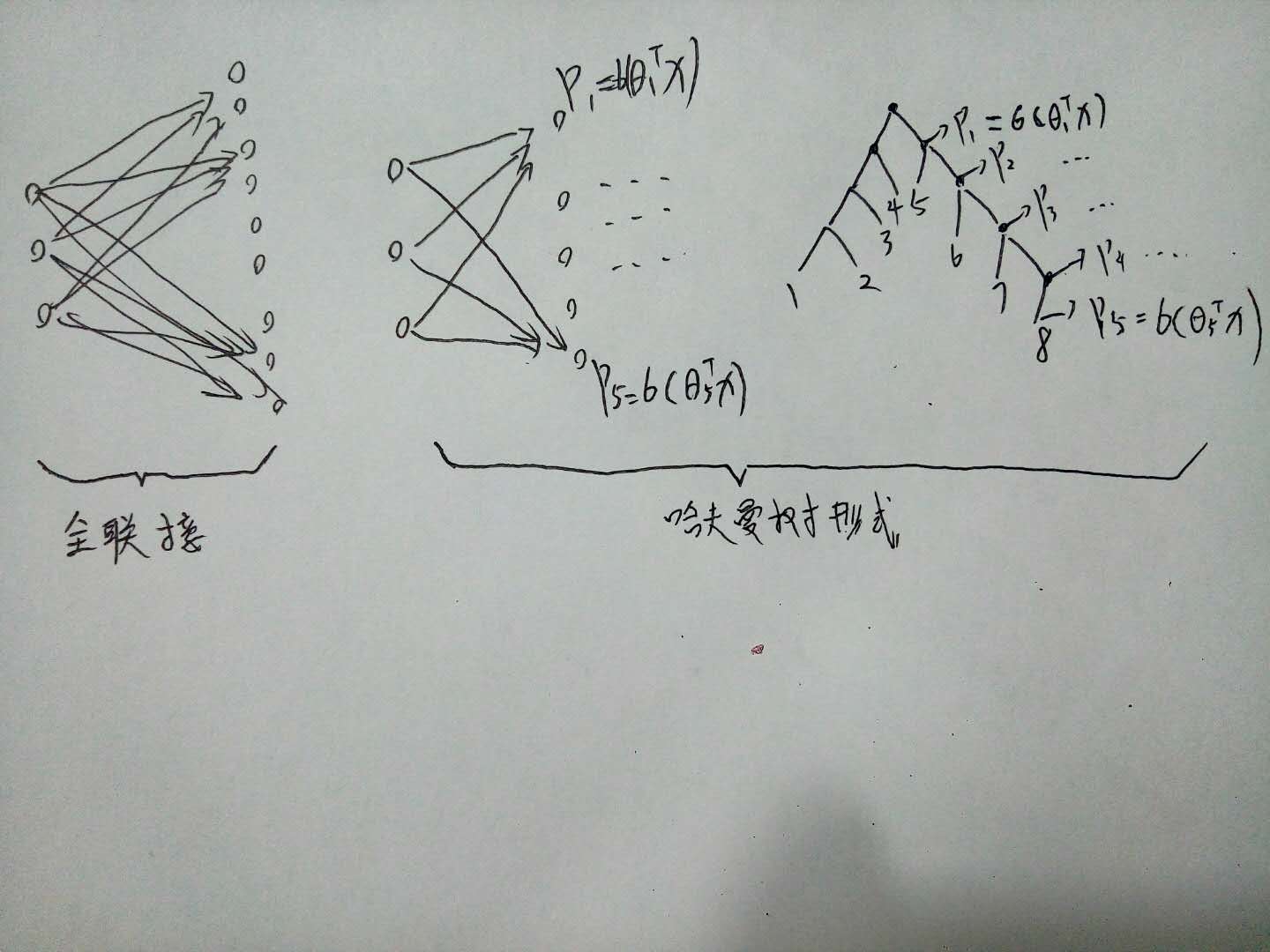
简化后训练Language model的神经网络如图所示,甚至都没有Hidden Layer层,是一个直接从input到output的映射。
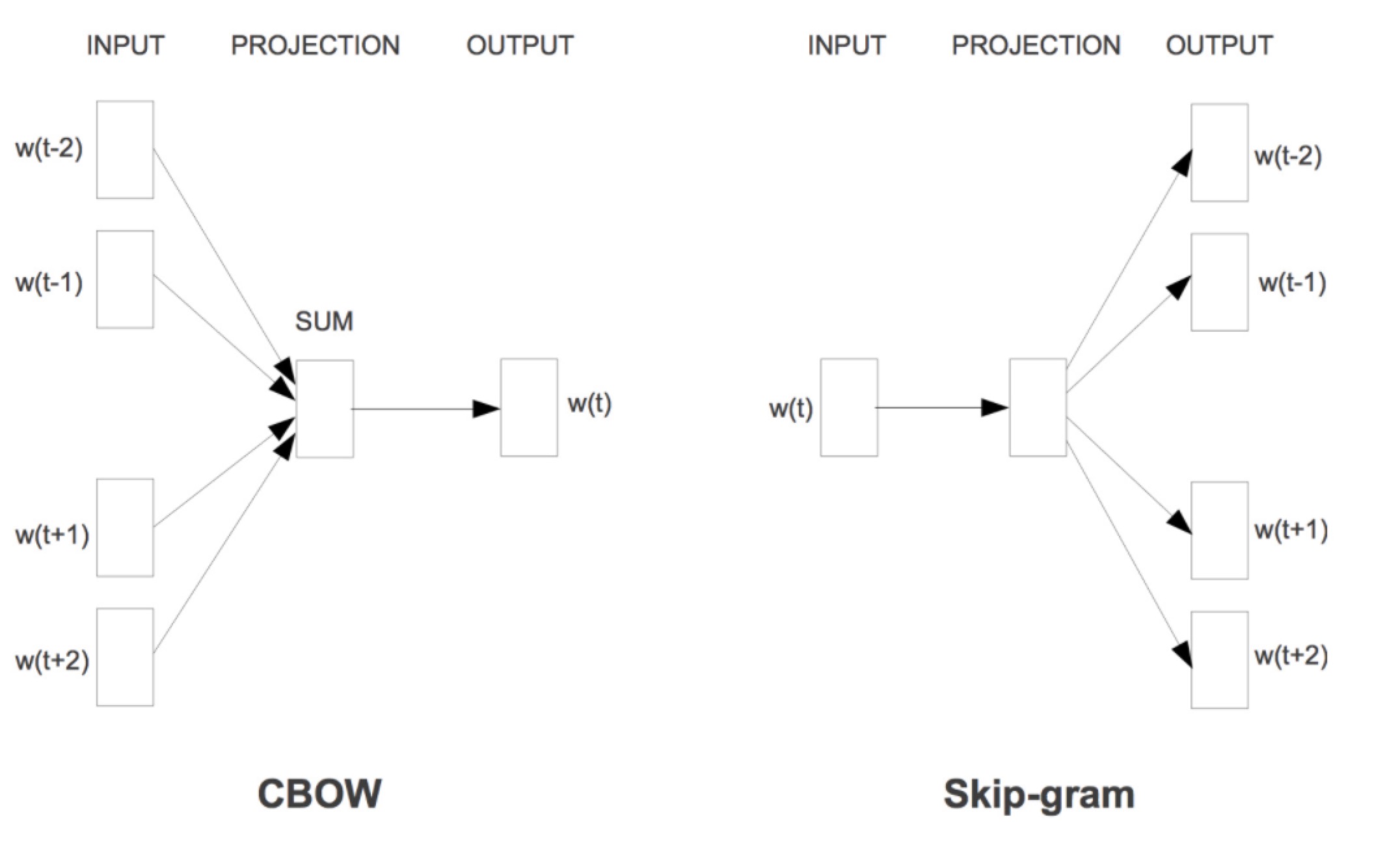
图中的三层含义:
input:上下文的词向量(注意我们训练的是CBOW语言模型,词向量只是模型的一个参数,起始时是个随机值)
projection:上下文词向量simply add(若是Skip-gram为input本身)
output:按理说此处应当是在词表维度C上的概率分布
参数化表示上面的CBOW语言模型后,如下图所示:(看这里更清楚了,这不就是纯粹的softmax公式么…)
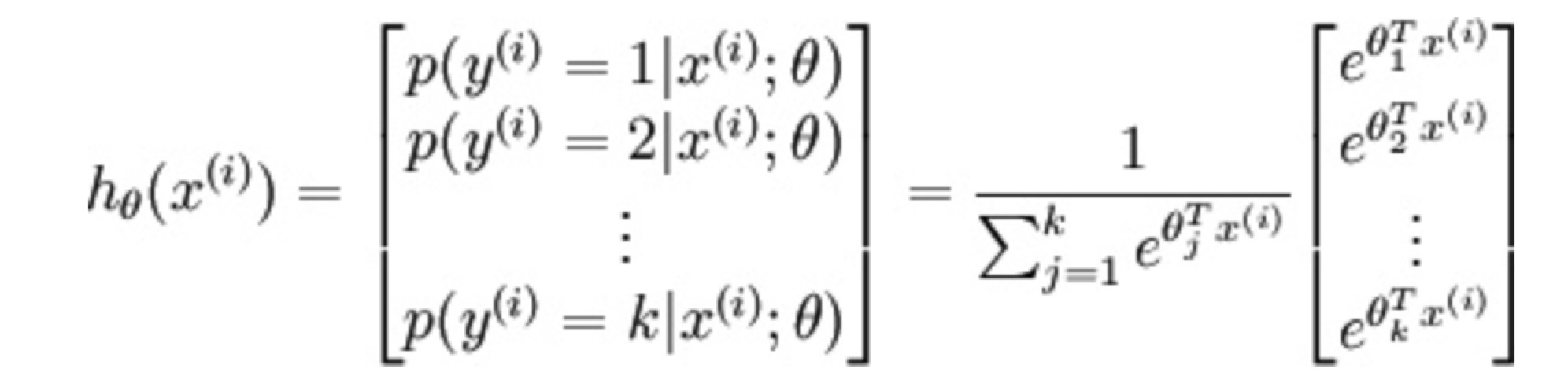
简单计算下这个网络从projection Layer到Output Layer 全连接网络层之间的参数:projection Layer即词向量维度在102量级;词表(Vocab)数量在105量级;语料库中需要训练的词汇数量一般在107量级以上。这样的运算次数是十分吓人的!
Hierarchical Softmax
重点:作者此处便采用了哈夫曼树的思想:具体做法是将语料库中的词按先词频排序,然后不断合并最小的两个节点成为一棵哈夫曼树,最终合并效果如下所示,词表中的所有词汇均为于树的叶节点上(详见:10分钟便能懂的公开课)
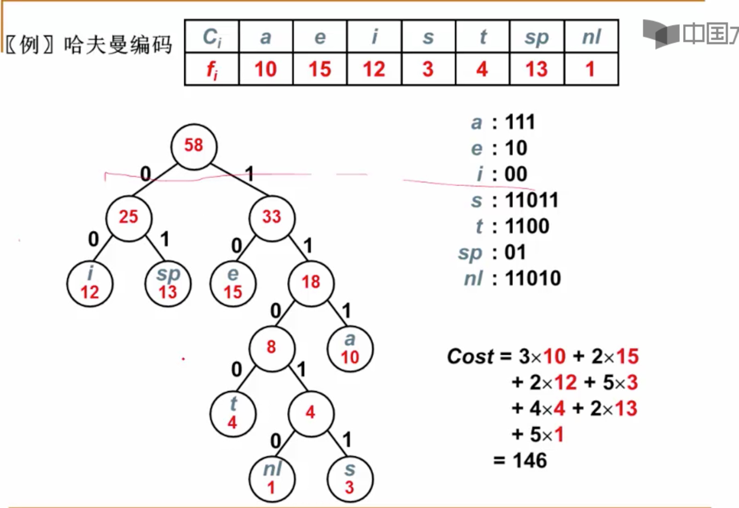
生成Target词汇的概率为从跟节点到叶子节点路径的概率连乘(见下图)。而哈夫曼树相比于其他形式的二叉树,将高频词赋予更短的编码,可以进一步减少概率P相乘次数。下面用图解的方式说明为什么采用哈夫曼树可以加快计算速度。
极限假设词向量维度为3,词表大小为20。那么全连接网络1次迭代需要训练的参数数量为60个,接着再进行softmax归一化。
哈夫曼树的形式,假设目标词汇是图中的节点8,根结点到8节点一共经过5个节点(哈夫曼树编码知识,8节点的编码表示为:11110,那么计算Target词汇概率,仅涉及3*5=15个参数的计算。
基于二叉树的这种性质,计算复杂度从之前的O(N)变为O(logN),运算速度指数级提升。
而Cost函数为对概率连乘取log对数,如下:
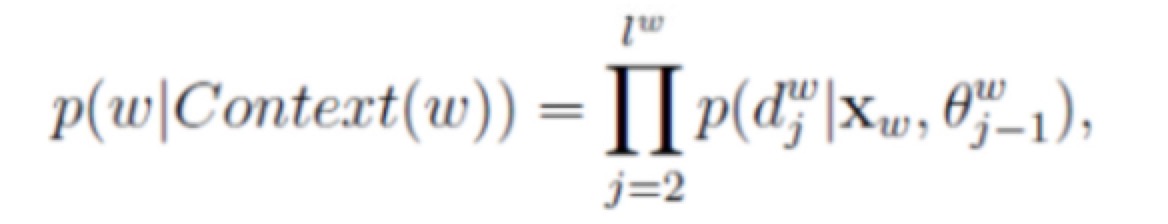
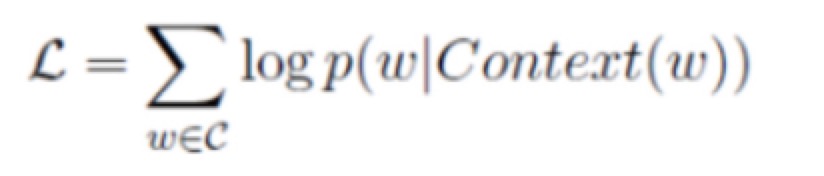
训练目标是最大化Cost函数,采用的算法是梯度上升。其实跟梯度下降非常类似,cost对参数向量取偏导数得到梯度,参数更新时候再加上该梯度乘learning rate就可以了,不过此处涉及两个参数向量,一个是权重theta,另一个就是词向量。此处直接复制Hankcs.com中的推导结果,两个参数更新方式如下:
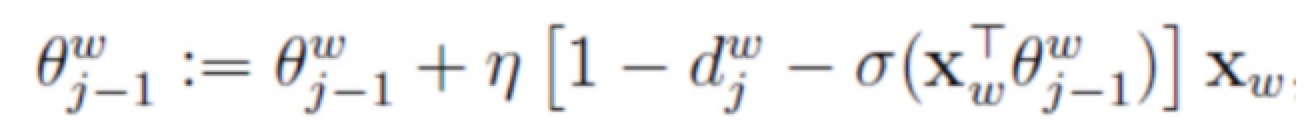
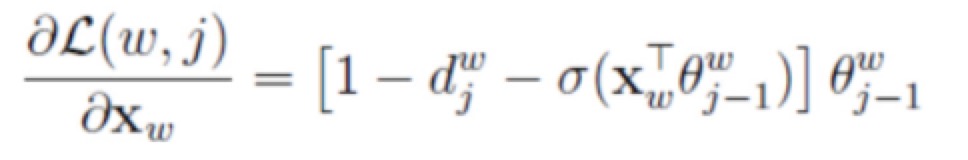
如此便完成了一次完整的训练周期!
更简单直白的总结是:扁平的softmax在计算P(y=j),需要计算整个词表每个词的概率,而现在分层的softmax只需要计算一条路径上节点的概率值,便可以得到P(y=j),接着进行梯度上升,不断使概率P变大
Negative sampling
定义:
由于Hierarchical Softmax对于频率较低的词汇,依然需要花费较长的步骤才能找到该词。所以作者引入了另一种算法:Negative sampling(sampled softmax),即:为了加快训练速度,在loss计算时,采用负采样方式,并不是求整个vocab的softmax概率,而是随机采样的W个。这样每次训练中就可以更新这少量的W个参数,其他参数被冻结(需要注意总的参数数量不变,只是每次参与迭代计算的数量锐减)。需要注意:在Test阶段,要到整个词表中softmax(此时词向量本身及其权重已经被计算了出来),来确定下一次选中的是哪些词汇(可接beam search)。若是哈夫曼树,Test时会找出一个确定的词
我们原来模型每次运行,假设词向量维度:300;vocab大小:1W,之前每次迭代需要跟新300W参数。现在负采样个数N=5。只要跟新300×(1+5)=1800,参数减少了非常多,训练速度大幅加快。
采样方法:
那怎样确定负采样个数N呢?其实就是随机抽取,但要考虑词频的影响,词频越高,越容易被抽出来。具体到word2vec中,作者是这样实现的:采用一个大小为M的table(M>>vocab size,一般取10^8)。分为M份,每份代表一个词,如图所示;
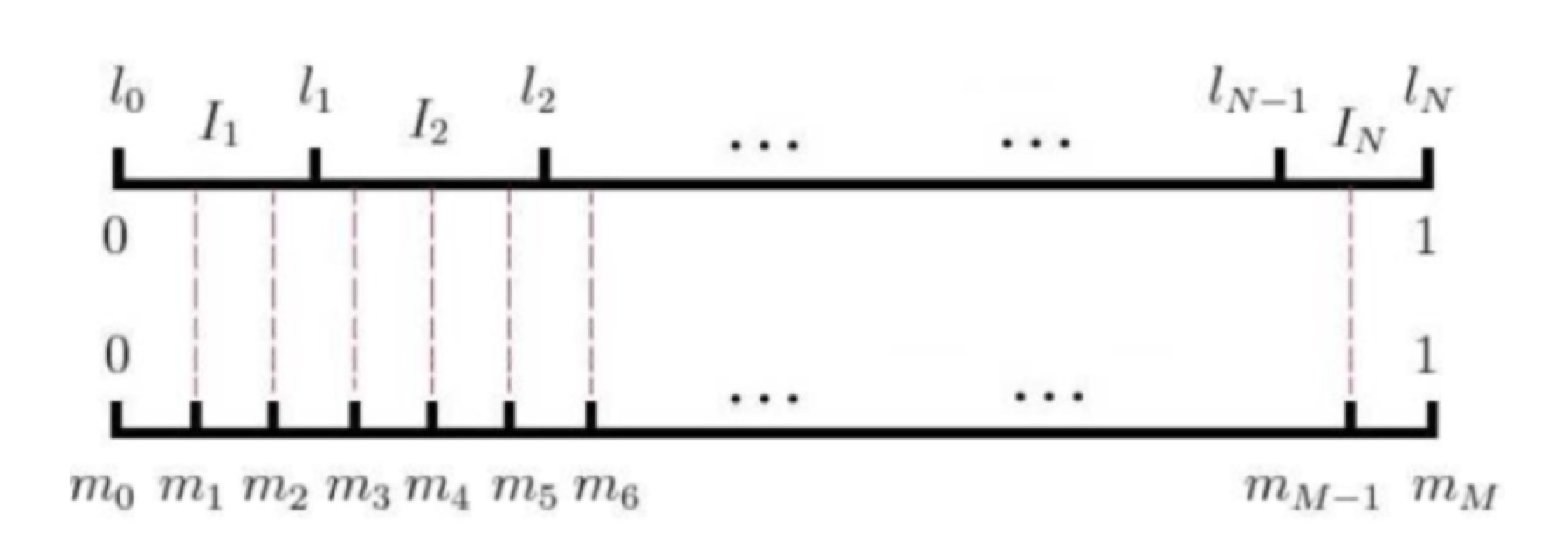
但具体怎么确定哪一份对应什么词呢?作者采用了如下的公示计算每个词的份额(对应在tabel上占据的长度)
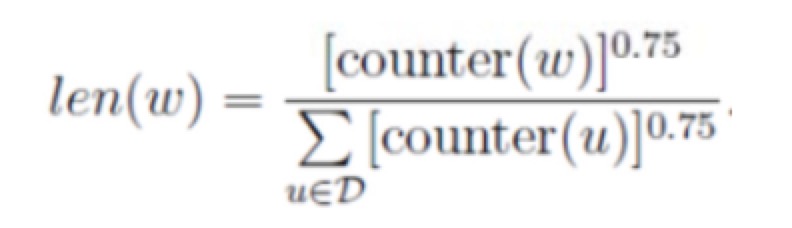
在paper中提到0.75这个超参是试出来的,实现的话就是直接1~M取一个随机数,从中提取对应的项便可以了。
Ref:
Blog:Word2vec原理推导与代码分析
Blog:Word2vec-知其然知其所以然
Blog:中文维基百科语料库词向量的训练
Blog:Word2vec教程-Negative Sampling
《word2vec中的数学原理详解》
《Tensorflow实战》