背景:
2012年5月,Google推出Google知识图谱(GoogleKnowledge Graph),并利用其在搜索引擎中增强搜索结果。这是“知识图谱”名称的由来,也标志着大规模知识图谱在互联网语义搜索中的成功应用。
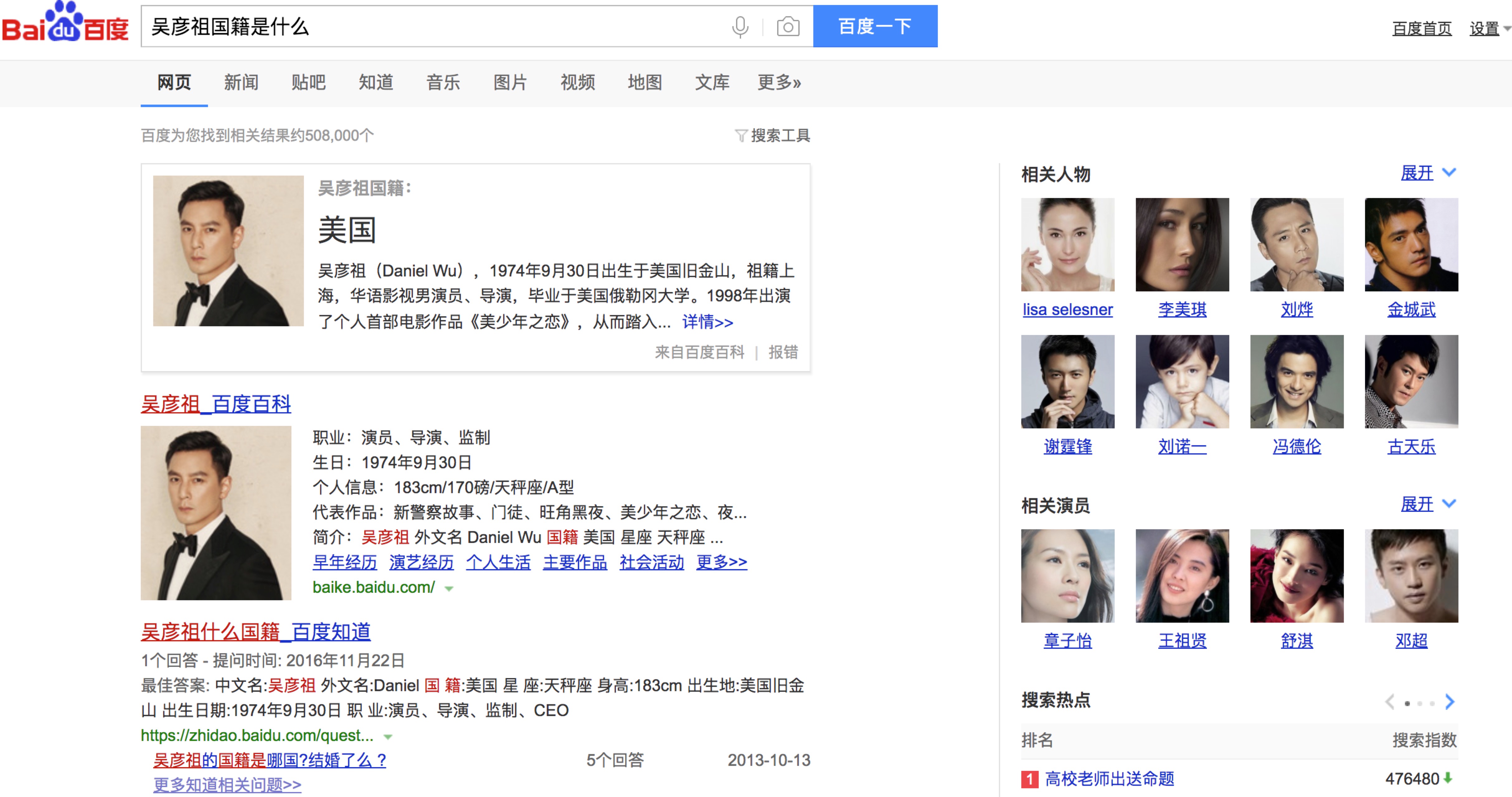
Eg:搜索“吴彦祖的国籍是什么?”,Google/Baidu会给出与之相关的详细搜索结果(可以叫“搜索++”或者“搜索杂烩且精准”,顺带提一句,搜索本身就是AI,没必要将其神秘化,之前到现在一只都有,只是如同其他任何一个行业,发展的越来越好,2012年后随着深度学习的爆发,迎来了一波小高潮)
知识图谱概念
定义:知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,其构成一张巨大的语义网络图,节点表示实体或概念,边则由属性或关系构成。
节点:知识图谱包括实体、属性/语义类、属性值、关系这么4种节点。最终以三元组的形式呈现,主要包括(实体1-关系-实体2)和(实体-属性-属性值)等。
中国-首都-北京是一个(实体-关系-实体)的三元组样例.
北京-人口-2069.3万是一个(实体-属性-属性值)的三元组样例。
构建:
知识图谱的构建技术包括3大方面:知识提取、知识表示、知识融合。后两方面自己目前的知识面尚未覆盖,仅就Deep Learning相关的来说,
知识提取部分又包括实体抽取、语义类抽取、属性和属性值抽取。
实体抽取目前有用
BiLstm+CRF算法来做;
语义类抽取笔者自己也尝试了用word2vec进行相似度匹配,效果还不错;
属性和属性值抽取,笔者尝试了用命名实体识别工具+正则匹配的方式也能完成一定程度的,像地名、场景、日期、车牌等信息的抽取。
目前工业界基本也是通过从半结构化的数据中抽取信息,而不是通过“阅读”句子产生真正的理解来抽取,深层自然语言处理这块儿骨头太硬了。
小结:
写到这里,笔者更认为深度学习也是构建知识图谱的一种方式,深度学习能较好解决机器翻译、客服对话等小任务,也是一定程度上对知识地综合理解,比如通过机器翻译,建立英语、中文之间的联系,通过Imagenet图像分类,建立1000种Object的对应关系。但,深度学习在NLP/图像中对“语义”的理解,还是太过单薄,设计太过简陋,面对这些非结构化的大量知识体系,无从下口、束手无策。
能够将知识图谱的各条“边”剥离清楚的,深度学习还需要再向前推进一大步,远不止目前的CNN、RNN…
而知识图谱本身的发展,应该要求更高,需要的是更加综合的知识。
——不能真正创造价值的概念,都是耍流氓!
话说回来吧,借助某位哲人说的,希望自己摒弃热潮,以工程任务为导向。首要解决当下NLP能解决的任务,这也是本博客名称“Deep coding”的由来。